

MapReduce计算模型与成本计算模型

探索大数据处理的编程框架及其经济影响
【MapReduce计算模型简介】
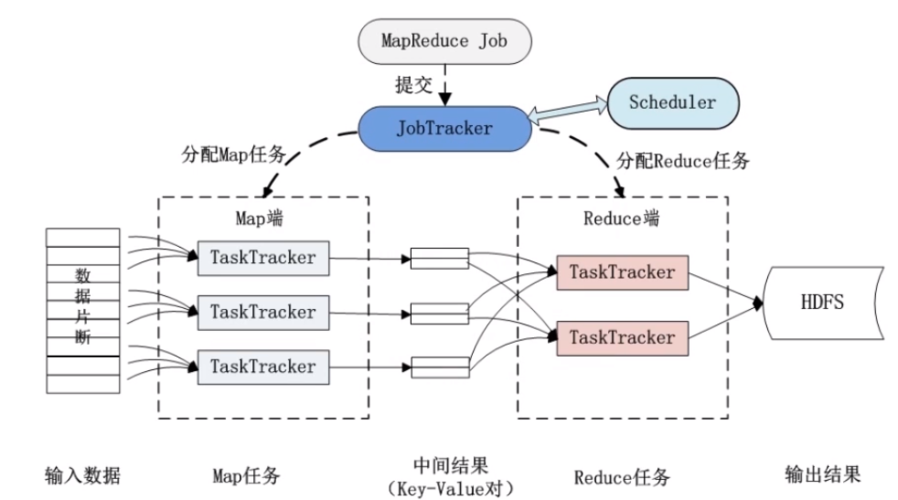
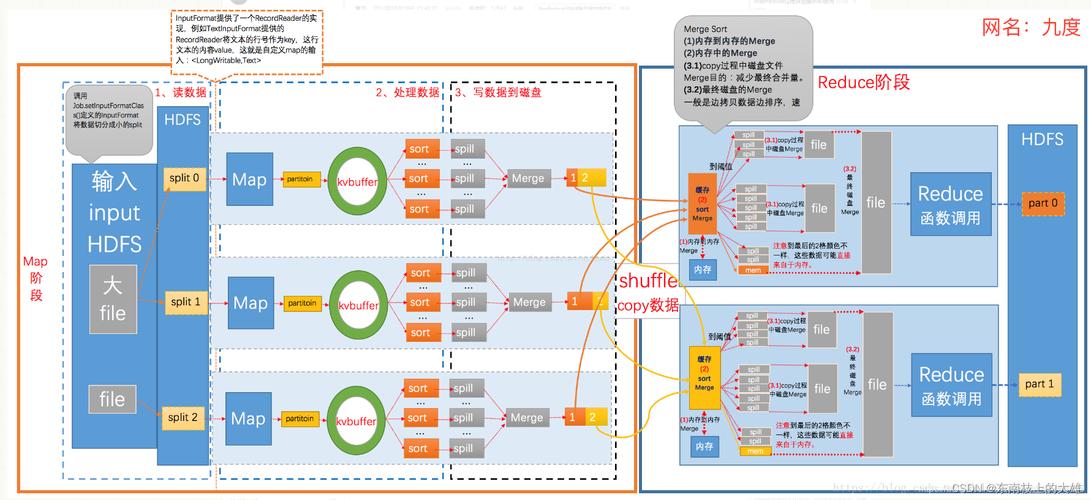
MapReduce是一种分布式并行计算模型,旨在简化大数据集的处理,它通过将复杂的计算过程抽象为两个基本操作—Map和Reduce—来处理大规模数据集。
【起源与发展】
起源: Google在2003年和2004年分别发表了关于GFS和MapReduce的论文,标志着这一模型的正式提出。
发展: 随后,Hadoop项目实现了MapReduce算法,使其成为大数据处理的主流工具之一。
【核心组件与工作原理】
Map函数: 对输入数据进行分解和处理,生成一组中间键值对。
Reduce函数: 合并所有具有相同键的中间键值对,以获得最终结果。
【成本计算模型】
成本计算模型是评估企业项目开发或服务成本的一系列方法和公式,这些模型帮助企业准确估算成本,从而制定有效的财务计划和市场策略。
【常见成本计算方法】
Walston_Felix模型: 用于预估软件开发工作量和时间的模型。
ABC成本法: 基于活动的成本核算系统,适用于精确成本分配和管理。
【MapReduce与成本计算模型的关联】
虽然MapReduce主要用于数据处理,但其运作成本可通过成本计算模型进行评估,使用Putnam模型可以估算MapReduce作业的开发和维护成本。
【性能优化与成本控制】
优化策略: 包括合理配置硬件资源、优化Map和Reduce函数的代码等。
成本控制: 通过优化作业执行时间和资源利用率来降低运营成本。
相关问题与解答
【问题1】如何选择合适的MapReduce框架?
答:选择MapReduce框架时,应考虑其兼容性、扩展性、社区支持和特定的功能需求,Apache Hadoop因其稳定性和广泛的应用场景而被广泛采用。
【问题2】成本计算模型在实际应用中有哪些挑战?
答:实际应用中的挑战包括数据的不完整性、市场波动对成本因素的影响以及模型参数的调整,企业需要持续监控市场变化并调整模型参数,以确保成本估算的准确性。
MapReduce模型通过简化数据处理流程,极大地推动了大数据技术的发展,结合成本计算模型,企业能够有效管理和控制数据处理项目的成本,实现经济效益的最大化,理解这两个模型的原理和应用,对于从事大数据处理和分析的专业人员来说至关重要。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/587514.html
 微信扫一扫
微信扫一扫