

MapReduce Job 依赖与配置全解析
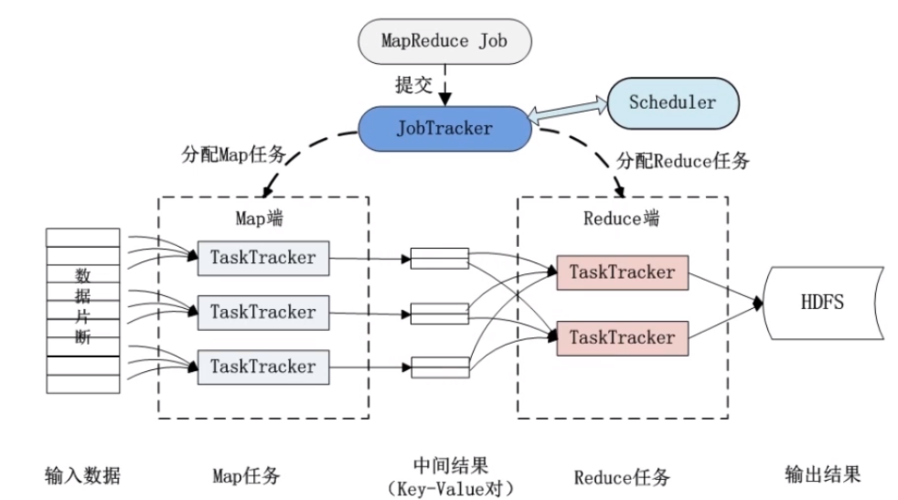

MapReduce是大规模数据处理的编程模型,在Hadoop等大数据框架中被广泛应用,合理配置MapReduce作业(Job)对于优化性能至关重要,本文将详细介绍如何配置MapReduce Job的依赖关系和基本设置,以帮助用户更好地理解和应用这一技术。
Job 配置基础
1. Job参数配置
输入输出路径:定义数据的来源和去向,确保数据的准确流动。
Mapper和Reducer类设置:选择适合数据处理需求的Mapper和Reducer类,这对数据处理逻辑非常关键。
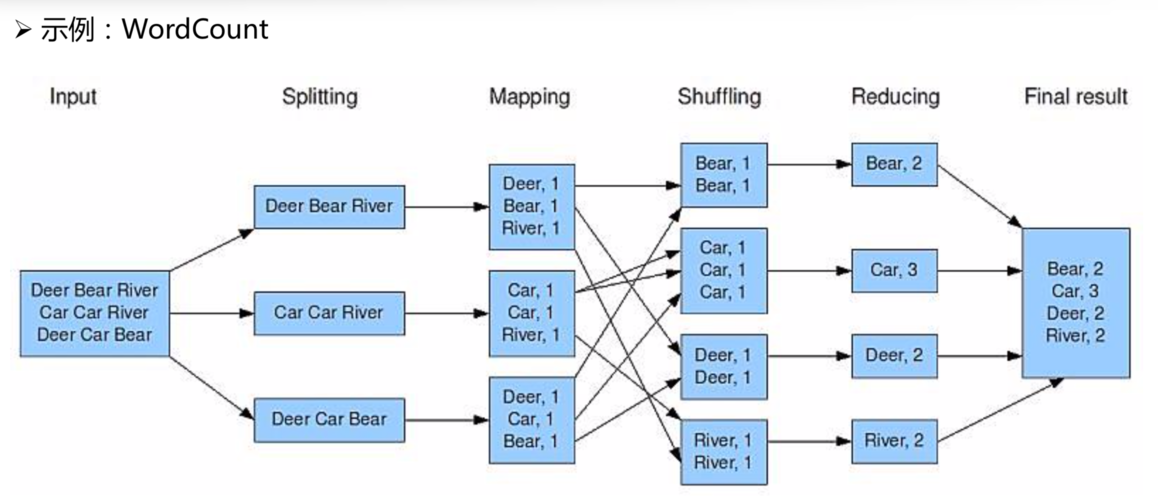
InputFormat和输出类型:选择合适的InputFormat以及正确设置输出的键值对类型,这对于数据的处理和结果的正确性至关重要。
2. 环境与提交
Hadoop环境配置:在开发环境中配置必要的Hadoop环境变量及库,确保Job能在Hadoop集群上运行。
作业提交:使用job.waitForCompletion()方法提交作业到资源调度器(如YARN),并等待其完成。
Job依赖管理
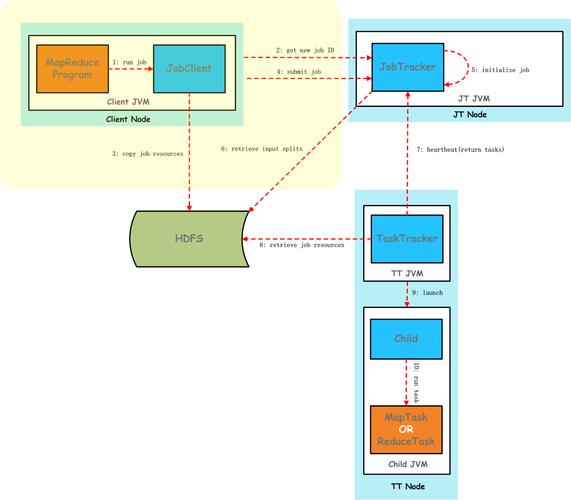
### 1. JAR文件打包
依赖打包:将所有必需的依赖项和类文件打包进一个JAR文件中,这有助于在集群中分发和执行作业,减少依赖项加载时间。
包含资源配置:如果作业需要访问其他服务或资源,确保相关的配置文件也包含在JAR文件中。
2. 动态库与通知配置
动态库加载:在Hadoop集群中正确加载和使用动态库,这可能涉及到特定的库文件和资源配置。
作业结束通知:通过配置mapreduce.job.endnotification.url属性,实现在作业完成时自动发送通知到指定URL,方便作业监控和管理。
Job基线设置与调优
1. 确定基线
基线的重要性:基线为优化提供参考标准,所有调优效果的评估都应与基线数据进行对比验证。
基线原则:确保每个任务的执行时间合理,充分利用集群资源,并在可能的情况下尽量减少reduce轮次。
2. 调整与优化
资源利用:通过调整数据量大小和map与reduce任务的数量,确保所有节点均有任务处理且保持忙碌状态,提高并发度和资源利用率。
通过精确配置MapReduce作业的依赖关系和基本设置,可以显著提升数据处理任务的效率和可靠性,从作业参数的配置、环境搭建,到依赖管理和作业监控,每一步都需要仔细考虑和适当的优化,设定合理的作业基线并进行持续的性能调优,对于发挥Hadoop集群的最大效能也是不可或缺的。
相关问题与解答
Q1: 如何确保MapReduce作业在集群中高效运行?
A1: 确保高效运行的关键在于合理配置作业参数(如输入输出路径、Mapper和Reducer类),优化资源利用(如适当设置reduce数量),以及确保所有依赖项被正确打包和加载。
Q2: 如果作业执行效率不理想,我该如何进行调优?
A2: 首先确定作业的基线性能,然后根据基线数据调整诸如数据块大小、并发任务数量等参数,监控作业执行过程,分析日志来发现潜在的性能瓶颈,并根据情况调整资源配置。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/587606.html
 微信扫一扫
微信扫一扫