

MapReduce统计前十_MapReduce统计样例代码

1. 数据准备
假设我们有一个文本文件,其中包含一系列数字,每个数字占一行,我们将使用这些数字作为输入数据来计算前十个最大的数字。
2. Map阶段
在Map阶段,我们将读取每一行数据,并输出一个键值对,其中键是固定的(quot;number"),值是当前行的数字。
def map(key, value):
# key: None
# value: 一行文本,包含一个数字
yield "number", int(value)
3. Shuffle阶段
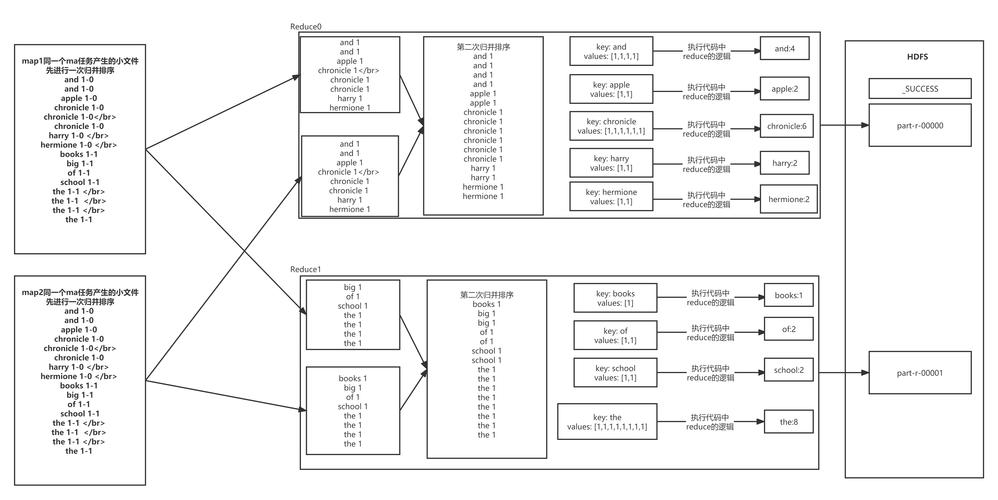
Shuffle阶段将根据键值对的键进行排序和分组,将所有具有相同键的值放在一起,在这个例子中,所有的键都是"number",所以所有的数字都将被放在一起。
4. Reduce阶段
在Reduce阶段,我们将处理所有具有相同键的值,我们将计算前十个最大的数字。
def reduce(key, values):
# key: "number"
# values: 包含所有数字的迭代器
top_ten = sorted(values, reverse=True)[:10]
for number in top_ten:
yield number
5. 完整的MapReduce代码示例
from mrjob.job import MRJob
class TopTenNumbers(MRJob):
def mapper(self, _, line):
yield "number", int(line.strip())
def reducer(self, key, values):
top_ten = sorted(values, reverse=True)[:10]
for number in top_ten:
yield number, None
if __name__ == '__main__':
TopTenNumbers.run()
问题与解答
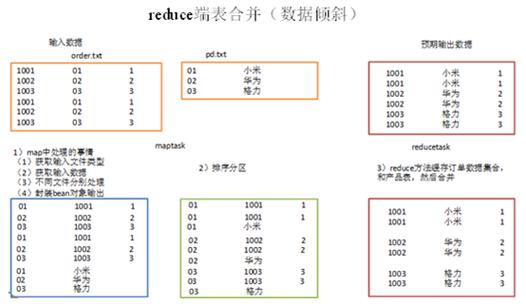
问题1: MapReduce中的shuffle阶段是如何工作的?
答案1: Shuffle阶段是MapReduce框架中的一个关键步骤,它负责将Map阶段的输出按照键值对的键进行排序和分组,它会将所有具有相同键的值收集到一起,并将它们发送到同一个Reduce任务进行处理,这个过程通常发生在Map阶段完成后,但在Reduce阶段开始之前。
问题2: 为什么我们需要在Reduce阶段计算前十个最大的数字?
答案2: 在MapReduce框架中,Reduce阶段的主要目的是对具有相同键的所有值进行聚合或汇总操作,由于我们的输入数据可能非常大,我们不能在Map阶段直接找到前十个最大的数字,因为这样会需要大量的内存和计算资源,通过使用Reduce阶段,我们可以在所有具有相同键的值上执行排序操作,并只选择前十个最大的数字,这样可以有效地减少数据处理的复杂性和所需的资源。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/587848.html
 微信扫一扫
微信扫一扫