

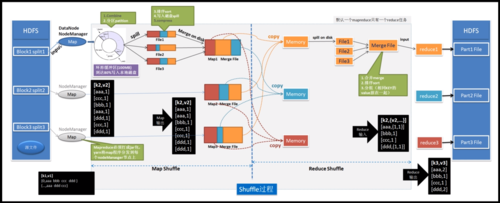
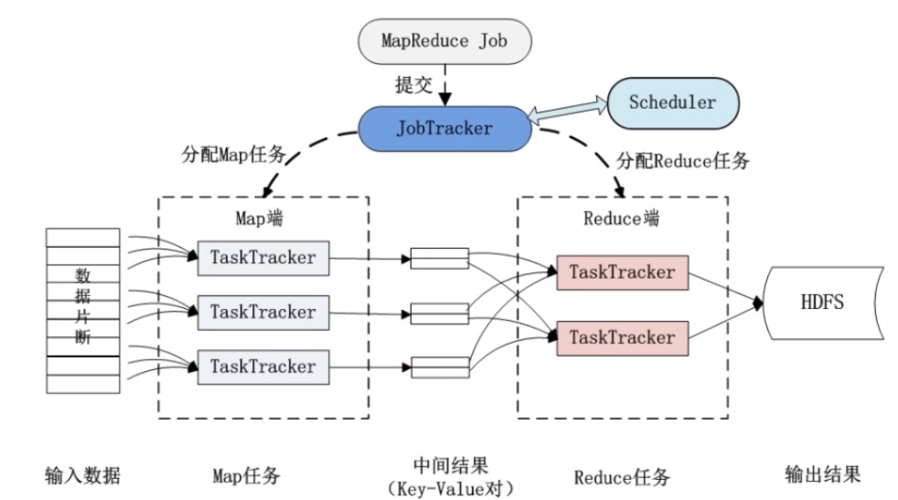
MapReduce中的Map端聚合是指在Map阶段对输出的键值对进行局部汇总,以减少数据传输量和减轻Reduce阶段的计算压力。这有助于提高整个MapReduce作业的性能和效率。
MapReduce Map端聚合

(图片来源网络,侵删)
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,在MapReduce中,Map端聚合是一种优化技术,通过在数据传递给Reduce阶段之前进行部分聚合操作,以减少网络传输的数据量和提高整体的处理性能。
Map端聚合是MapReduce框架中一种常用的优化方法,通过实施此策略,可以有效减少数据处理过程中的网络传输量,从而提高大数据处理的效率,这种优化技术虽然增加了计算的复杂性,但对资源的节省及性能的提升使其成为大数据处理不可或缺的一部分,通过合理配置和使用Map端聚合,用户可以在保证数据完整性和准确性的同时,优化他们的大数据处理流程。
(图片来源网络,侵删)
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/587875.html
 微信扫一扫
微信扫一扫