

FPGrowth算法与MapReduce框架的结合
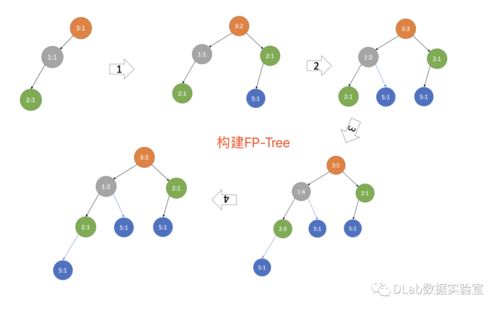

FPGrowth算法是一种高效的频繁项集挖掘算法,它通过构建FP树(Frequent Pattern Tree)来避免生成候选项集,从而减少了搜索空间,提高了算法的效率,在面对海量数据集时,单机环境下的FPGrowth算法可能面临内存不足的问题,将FPGrowth算法与MapReduce框架结合成为解决这一问题的有效手段。
基本思想与实现步骤
1、FPTree的构建:
在MapReduce框架下,FPTree的构建过程被分配到多个节点上执行,每个节点负责数据集的一个子集,并行构建本地FP树。
通过Map函数完成数据的划分和本地FP树的构建。
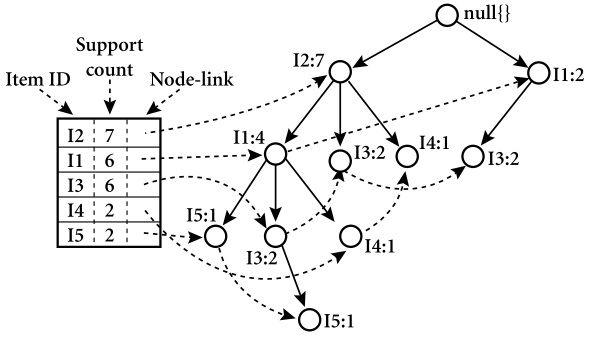
2、从FPTree中递归挖掘频繁项集:
利用Reduce函数整合各节点的本地FP树,递归挖掘全局频繁项集。
结合分布式缓存机制存储F_List表提高访问效率,降低I/O操作。
3、负载均衡与分组策略:
通过负载均衡分组策略,平衡各个节点的压力,充分利用各个节点的计算能力。
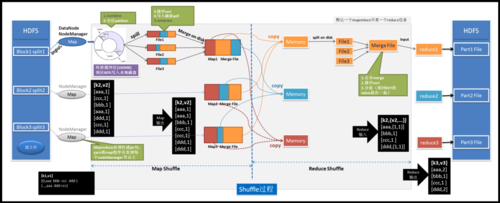
4、MapReduce任务完成频繁项集的挖掘:
MRFP算法通过两次MapReduce作业来提高效率。
第一次计算得到1频繁项集的支持度,第二次直接构建条件树,跨过了传统FPGrowth构建完整的FPTree的过程。
5、开源项目中的应用:
在Apache的开源项目Mahout中,已经实现了基于MapReduce的FPGrowth算法,可以直接使用。
数据结构与算法优化
1、FP树的数据结构:
FP树是一种压缩的树结构,用于存储频繁项集信息,包括项头表和项前缀路径。
通过这种结构,FPGrowth算法能够高效地挖掘出所有的完备频繁模式。
2、算法优化:
通过只扫描两次数据集,FPGrowth算法显著提高了运行效率。
引入了特定的数据结构来临时存储数据,如项头表和条件FP树,进一步优化了算法性能。
上文归纳与展望
1、算法性能提升:
结合MapReduce框架,FPGrowth算法能够处理大规模数据集,解决了内存限制问题。
通过分布式计算,算法的整体性能得到了显著提升。
2、未来研究方向:
随着大数据技术的发展,如何进一步优化FPGrowth算法在MapReduce框架下的性能和可扩展性是未来的研究方向。
探索更高效的数据结构或算法改进方法,以适应更大规模和更复杂数据集的需求。
相关问题与解答
Q1: FPGrowth算法在MapReduce框架下的并行化处理主要解决了哪些问题?
A1: FPGrowth算法在MapReduce框架下的并行化处理主要解决了以下问题:
内存限制问题:通过将FP树的构建和挖掘过程分布到多个节点上,避免了单个节点内存不足的问题。
计算效率问题:并行化处理加快了FP树的构建和频繁项集的挖掘速度,提高了整体算法的效率。
可扩展性问题:MapReduce框架使得FPGrowth算法能够轻松扩展到更大的数据集和更多的计算资源上。
Q2: 在实际应用中,如何选择合适的MapReduce任务数量来优化FPGrowth算法?
A2: 在实际应用中,选择合适的MapReduce任务数量来优化FPGrowth算法需要考虑以下因素:
数据集大小:较大的数据集可能需要更多的Map任务来并行处理。
集群资源:根据集群中的节点数量和每个节点的资源(如CPU、内存),合理分配Map和Reduce任务的数量。
算法特性:考虑到FPGrowth算法的特点,如FP树的构建和频繁项集的挖掘过程,以及数据分布的均匀性,来决定任务的划分。
性能测试与调优:通过实际运行测试,观察不同任务数量对算法性能的影响,进行相应的调整和优化。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/587907.html
 微信扫一扫
微信扫一扫