

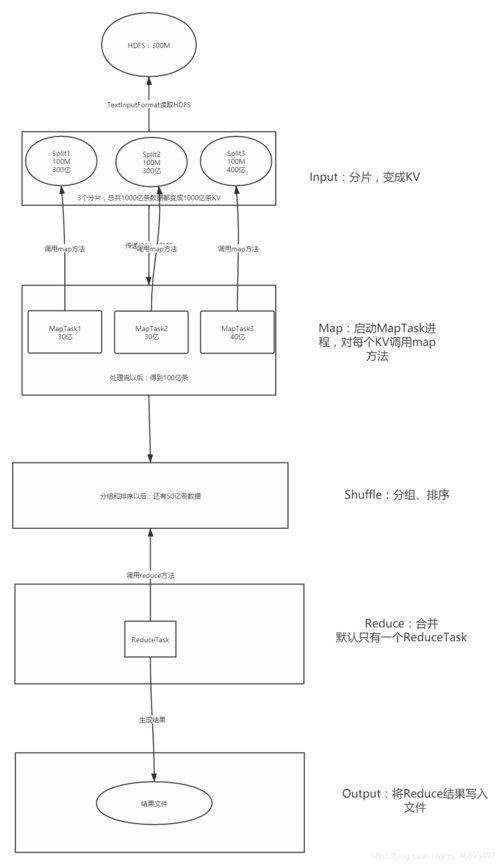

mapreduce是一种编程模型,用于处理和生成大数据集,在mapreduce框架中,文件分割(splitting)是一个关键步骤,它决定了如何将输入数据分配给各个map任务,小编将详细介绍文件分割的过程以及如何进行分区。
文件分割的概念
文件分割是将一个大文件划分为多个小文件的过程,每个小文件称为一个split,这个过程通常由框架自动完成,但用户也可以自定义分割逻辑。
分割过程
1、确定split大小:根据hadoop集群的配置,每个split默认大小通常为128mb或64mb。
2、逻辑分割:根据上述大小,框架将输入文件逻辑上分割成若干个split。
3、物理分割:在某些情况下,如果文件格式支持,如text files,可以进行物理分割,直接按照逻辑分割的大小切分文件。
4、分割与block的关系:每个split尽量与一个物理的block对应,以减少网络传输开销。
5、split与map任务:每个split将由一个map任务处理。
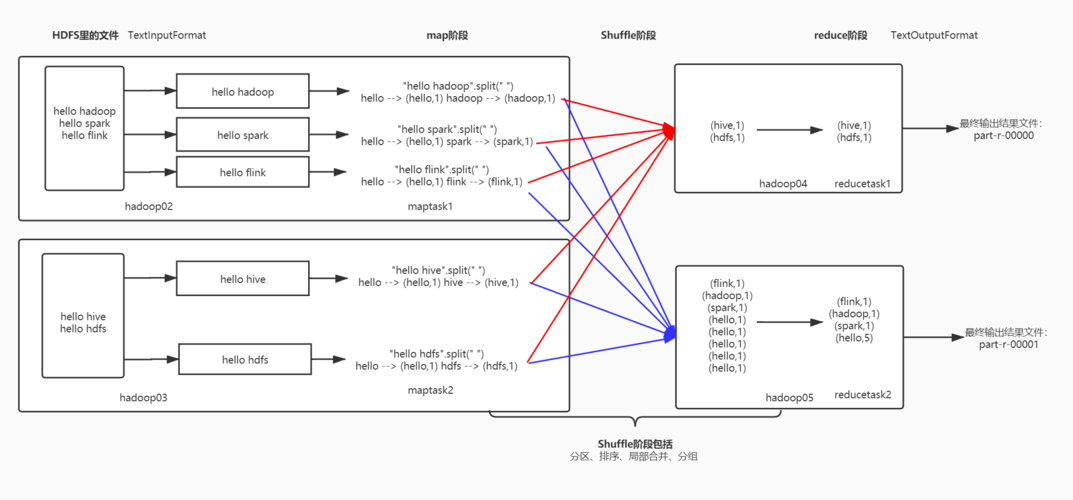
分区(partitioning)
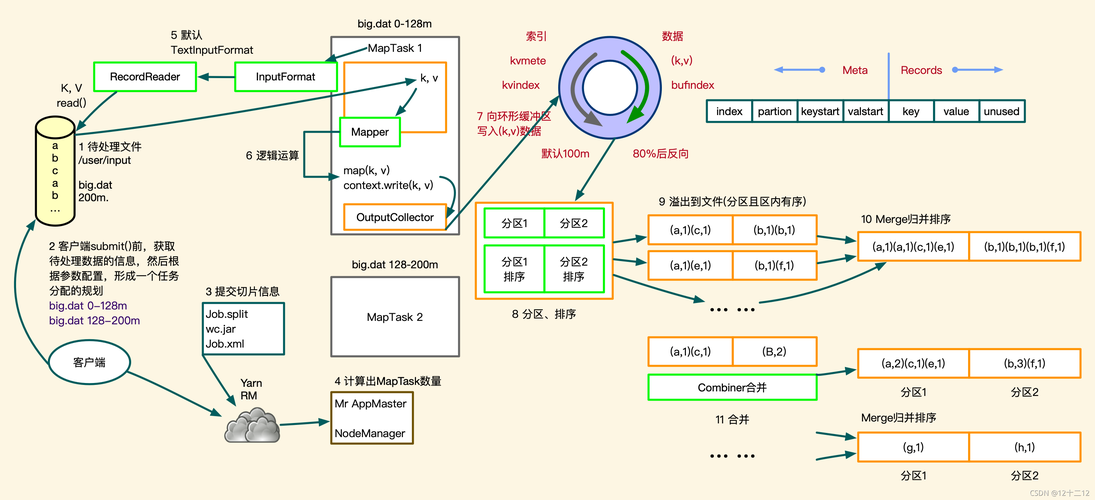
分区是mapreduce中将map输出的数据分发到reduce阶段的过程,用户可以自定义分区函数来控制数据如何被分配到不同的reducers。
1、默认分区:默认的分区机制通常是基于key的hash值模reduce任务的数量。
2、自定义分区:用户可以创建自定义partitioner类来实现特定的分区逻辑。
3、分区与shuffle:分区后的数据将在shuffle阶段被发送到相应的reducer。
相关问题与解答
q1: 如果输入文件小于一个split的大小,mapreduce还会创建一个split吗?
a1: 是的,即使输入文件小于一个split的大小,mapreduce仍然会为该文件创建一个split,并由一个map任务处理。
q2: 如何在mapreduce中实现二次排序?
a2: 二次排序可以通过自定义partitioner和comparator来实现,需要创建一个自定义partitioner,它将key分组并确保相同组的keys被发送到同一个reducer,在reducer中,使用一个自定义comparator来对keys进行二次排序,这样,可以在不同的reducers中分别对不同的key组进行排序,从而实现全局的二次排序效果。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/588024.html
 微信扫一扫
微信扫一扫