

在MapReduce框架中,心跳机制是维持集群健康状态的关键部分,小编将详细分析MapReduce中的心跳机制及其功能和实现方式。
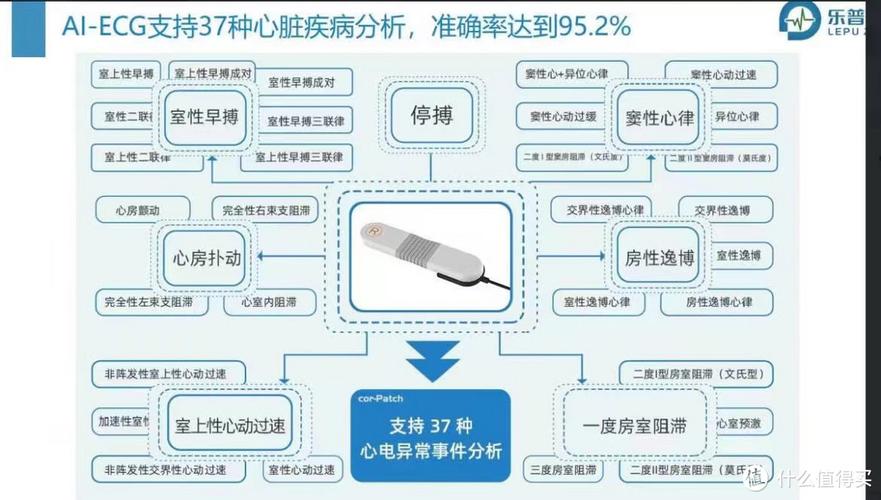
心跳机制的功能
1、监控节点健康状态
检测TaskTracker是否存活:心跳能够周期性地验证TaskTracker的运行状态,确保其仍在正常工作。
资源使用情况反馈:通过心跳,JobTracker可以实时获取每个TaskTracker上的资源使用情况,包括CPU、内存等的使用率。
任务运行状态信息:心跳还携带了任务执行的状态信息,如任务完成度、失败次数等,便于JobTracker做出调度决策。
2、任务分配与管理
任务分配:JobTracker通过心跳响应向TaskTracker分配新任务或调整现有任务。
错误处理:当TaskTracker上的任务失败时,JobTracker可以通过心跳机制获知并迅速进行任务重新调度。
优化资源利用:根据TaskTracker的资源使用情况,JobTracker可以更合理地分配任务,优化整个系统的资源利用率。
心跳机制的实现方式
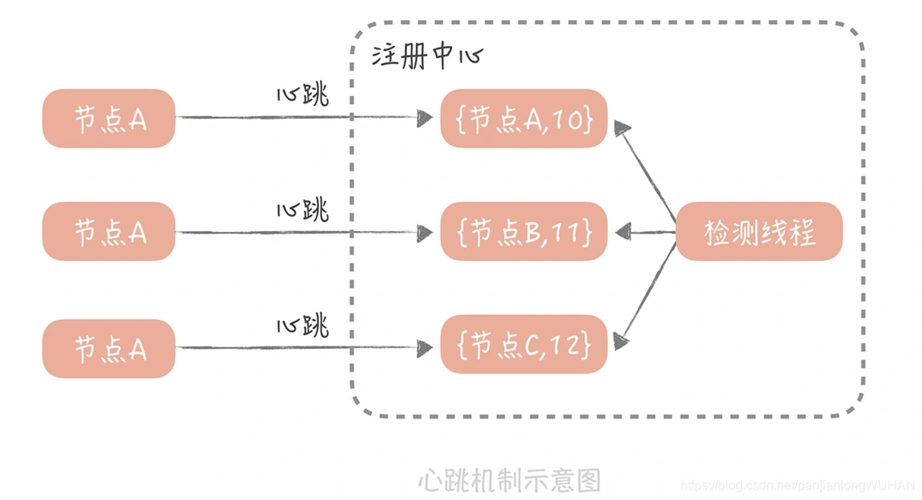
1、通信模式
RPC函数:心跳是通过一个RPC函数实现的,TaskTracker通过调用此函数向JobTracker发送心跳信息。
周期性调用:每个TaskTracker会定期调用heartbeat()函数,向JobTracker报告自己的状态并接收任务。
信息汇总与反馈:JobTracker收集所有TaskTracker的心跳信息,根据这些信息调整任务分配策略并反馈给TaskTracker。
2、数据处理流程
状态更新:JobTracker会根据收到的心跳信息更新其内部的数据结构,以维护整个集群的实时状态。
任务调度:基于TaskTracker报告的状态,JobTracker会做出任务调度决策,并通过心跳响应下达相关指令。
故障处理:一旦检测到TaskTracker故障或任务失败,JobTracker会立即进行任务恢复操作。
问题与解答
Q1: 如何调整心跳频率来适应不同的工作负载?
答:调整心跳频率可以通过修改TaskTracker的心跳间隔参数来实现,增加心跳频率可以使得JobTracker更快地获得集群状态,适用于对实时性要求高的场景;减少心跳频率则能降低网络和处理开销,适用于任务执行比较稳定的情况。
Q2: 心跳机制失效的影响是什么?
答:心跳机制若失效,JobTracker将无法及时获得各个TaskTracker的状态,也无法有效分配和管理任务,这可能导致故障延迟处理、资源利用率下降、任务执行效率降低等问题。
MapReduce中的心跳机制是保障集群高效运作的重要环节,它不仅负责监控节点的健康状态,还涉及到任务的分配与管理,了解和合理配置心跳机制对于维护和优化Hadoop集群的性能至关重要。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/588093.html
 微信扫一扫
微信扫一扫 