

MapReduce默认排序规则详解

MapReduce框架在处理大数据时,默认会对输出的键值对进行排序,这种排序机制对于优化数据处理流程、减少数据传输量以及提高任务执行效率至关重要,以下是关于MapReduce默认排序规则的详细介绍:
默认排序规则
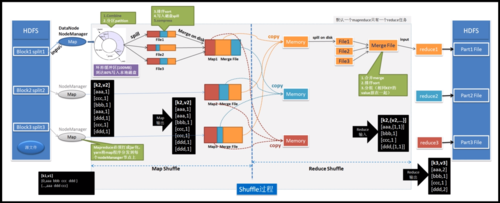
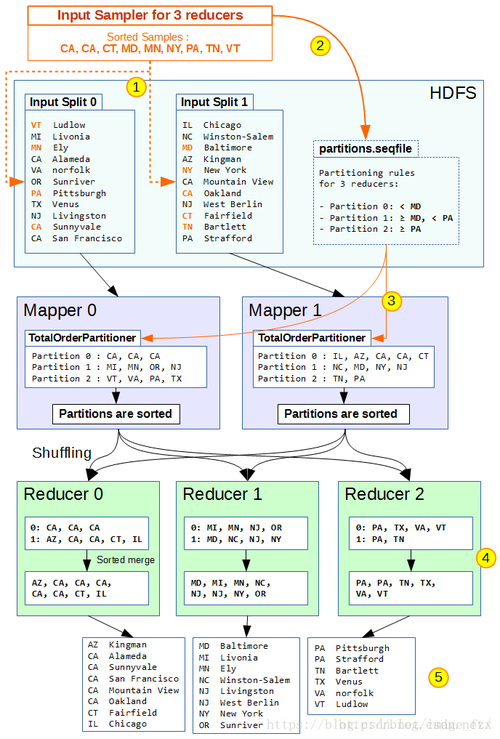
MapReduce框架中的排序主要分为两个阶段:Map阶段的排序和Reduce阶段的排序,在Map阶段的输出端,框架会对输出的键值对按键(Key)进行内部排序,而在Reduce阶段开始之前,框架还会对所有Map输出的键值对进行一次全局排序。
Map阶段排序
内部排序:每个Map任务完成后,其输出的键值对会按照键进行内部排序。
溢出文件:Map任务输出的键值对写入到环形缓冲区,当缓冲区达到一定阈值时,会将数据写入到磁盘上的溢出文件中。
分区:Map阶段的输出会根据分区函数分发到不同的Reduce任务。
Reduce阶段排序
合并:来自不同Map任务的输出会根据键进行合并,这个过程通常被称为“Shuffle”。
全局排序:在Reduce任务开始之前,所有输入的键值对会进行一次全局排序。
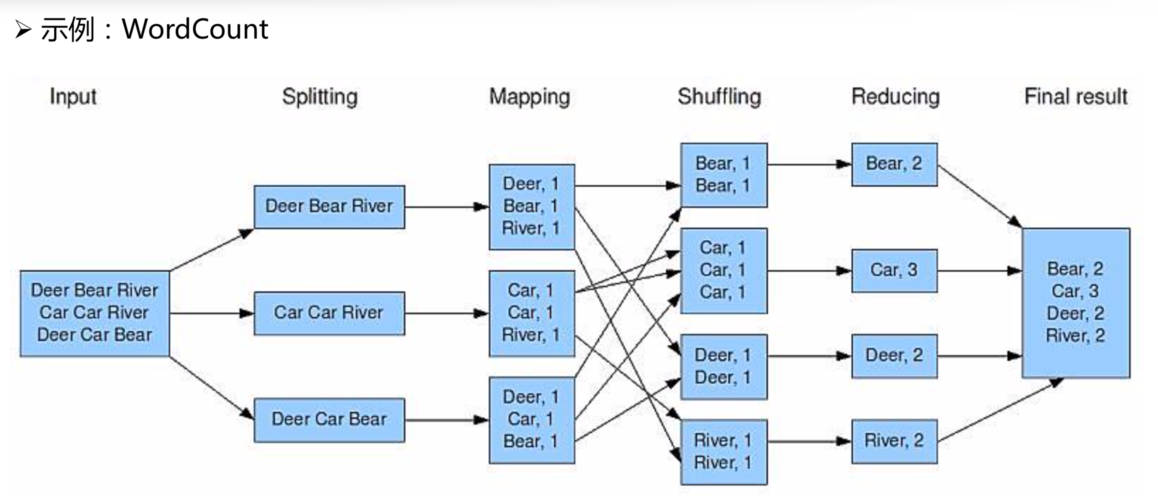
Reduce处理:排序后的键值对会被喂给Reduce任务进行处理。
排序算法
MapReduce框架中通常使用的排序算法是快速排序或者归并排序,这些算法在处理大规模数据集时表现出良好的性能。
自定义排序规则
用户可以通过实现WritableComparable接口来自定义排序规则,如果需要按照字符串长度而非字典序来排序,可以实现该接口并重写compareTo方法。
相关问题与解答
Q1: MapReduce中的排序是否可以关闭?
A1: 不可以,MapReduce框架设计之初就假设了排序是必须的,因此用户无法关闭这个特性,用户可以通过自定义Partitioner来控制数据如何分发到Reduce任务,从而间接影响排序行为。
Q2: 如果我想在MapReduce中实现自定义的排序逻辑,我应该如何操作?
A2: 要实现自定义的排序逻辑,你需要做以下几步:
1、创建一个类实现WritableComparable接口。
2、重写compareTo方法,实现你的比较逻辑。
3、使用JobConf的setOutputKeyClass和setOutputValueClass方法设置你的自定义键类和值类。
4、如果你的自定义比较逻辑改变了分区逻辑,你可能还需要实现一个自定义的Partitioner类,并通过setPartitionerClass方法设置它。
通过上述步骤,你就可以在MapReduce作业中使用自定义的排序规则了。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/588224.html
 微信扫一扫
微信扫一扫