

sql,SELECT 列名, COUNT(列名) ,FROM 表名 ,GROUP BY 列名 ,HAVING COUNT(列名) > 1;,`,,请将列名和表名`替换为实际的列名和表名。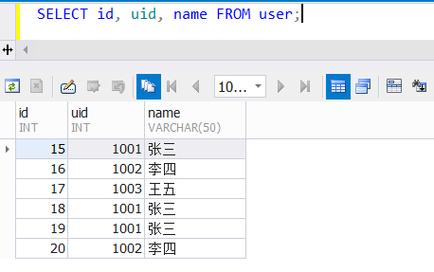

在MySQL中,我们可以使用多种方法来查找重复的数据,以下是一些常用的方法:
1. 使用GROUP BY和HAVING子句
这种方法适用于查找表中某一列或多列的重复值,如果我们有一个名为users的表,其中包含id,username, 和email列,我们想找出有相同email的所有用户,可以使用以下查询:
SELECT email, COUNT(*) as count FROM users GROUP BY email HAVING count > 1;
这将返回所有重复的电子邮件地址及其出现的次数。
2. 使用自连接
另一种方法是使用自连接来查找重复的数据,这种方法可以用于查找整个行的组合是否重复,如果我们想要找出users表中所有完全相同的行(即所有列的值都相同),可以使用以下查询:
SELECT u1.* FROM users u1 JOIN users u2 ON u1.id < u2.id AND u1.username = u2.username AND u1.email = u2.email;
这将返回所有完全相同的行。
3. 使用窗口函数
如果你使用的是MySQL 8.0或更高版本,你可以使用窗口函数来查找重复的数据,要找出具有相同email的所有用户,可以使用以下查询:
SELECT id, username, email, COUNT(*) OVER (PARTITION BY email) as count FROM users;
这将返回一个结果集,其中包括每个用户的ID、用户名、电子邮件以及该电子邮件的出现次数。
相关问题与解答
问题1: 如何在MySQL中查找具有特定条件的重复数据?
答案1: 你可以在上述查询中使用WHERE子句来添加特定的条件,如果你想查找users表中status为'active'并且email相同的用户,可以使用以下查询:
SELECT email, COUNT(*) as count FROM users WHERE status = 'active' GROUP BY email HAVING count > 1;
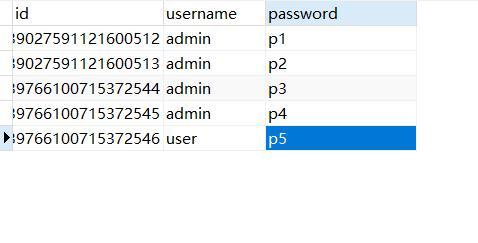
问题2: 如何删除MySQL中的重复数据?
答案2: 删除重复数据通常需要先确定哪些行是重复的,然后只保留唯一的记录,一种常见的方法是使用临时表,创建一个临时表并插入不重复的数据,然后删除原表并将临时表重命名为原表名。
CREATE TABLE temp_users AS SELECT DISTINCT * FROM users; DROP TABLE users; ALTER TABLE temp_users RENAME TO users;
这种方法会删除所有重复的行,只保留第一个出现的行,如果你希望保留最新的记录或其他特定记录,可能需要更复杂的逻辑来确定哪些行应该被保留。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/588355.html
 微信扫一扫
微信扫一扫