

MapReduce与Spark的对比分析以及华为云MapReduce服务(MRS)的介绍
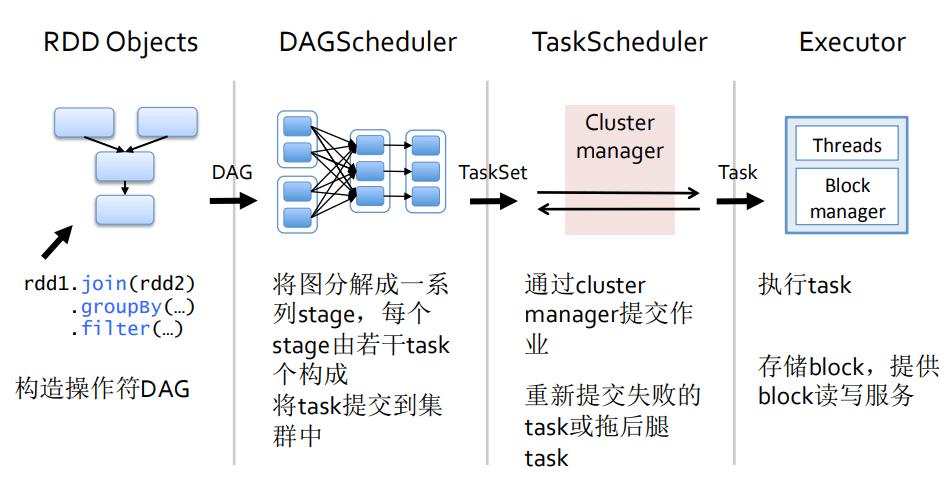

MapReduce与Spark的基本差异
1、数据存储方式:
MapReduce:主要基于磁盘处理,将中间结果保存到磁盘中,减少了内存占用。
Spark:基于内存计算,中间结果保存在内存中,提高数据处理速度和效率。
2、计算模型:
MapReduce:采用严格的两阶段模型(映射归约),所有操作需通过磁盘读写。
Spark:构建DAG(有向无环图),减少shuffle和磁盘IO操作,优化计算流程。
3、容错机制:
MapReduce:依赖于硬盘驱动器,失败后可以从中断处恢复。
Spark:提供RDD血缘机制和checkpoint,失败后可通过血缘机制重新计算。
4、适用场景:
MapReduce:适合批量处理大规模数据。
Spark:支持流处理和批处理,适合需要快速迭代的低延迟作业。
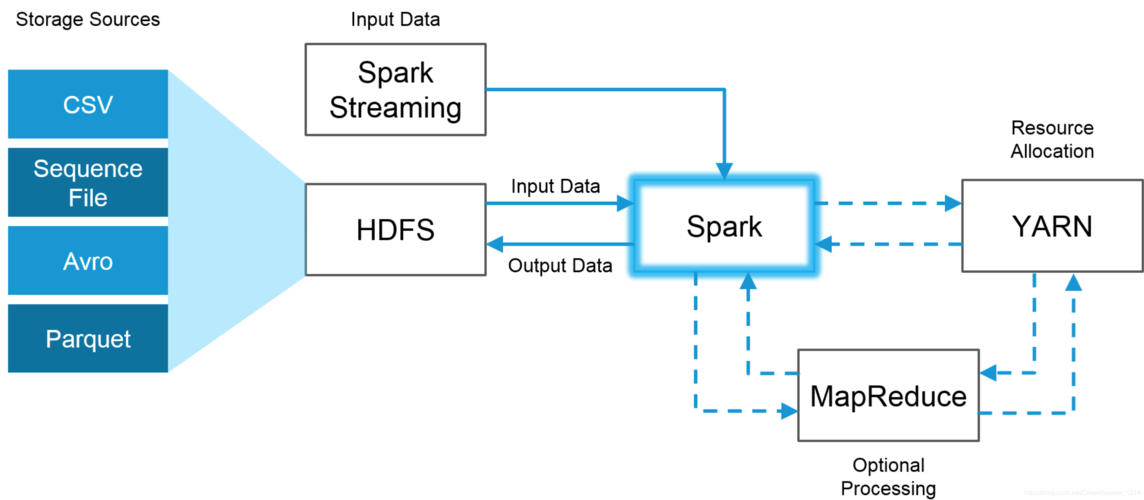
二、华为云MapReduce服务(MRS)
1、功能介绍:
MRS提供一键部署Hadoop集群的能力,用户无需关注硬件的购买和维护。
支持多种大数据组件,如Hadoop、Spark、HBase、Kafka等。
2、兼容性与安全性:
完全兼容开源接口,确保技术生态的完整性。
提供企业级的安全保证,保护数据安全和知识产权。
3、成本与效率:
低成本解决方案,避免了本地基础设施的高昂投资。
提升数据处理效率,加速大数据项目的实施周期。
应用案例与实践建议
1、选择依据:
根据数据量、实时性需求及预算选择适合的数据处理框架。
评估现有团队的技术栈和经验,选择合适的服务模式。
2、实施策略:
逐步迁移现有数据处理任务到云平台,评估性能和成本效益。
利用云服务的弹性扩展能力,应对数据量的动态变化。
常见问题解答
Q1: Spark与MapReduce在实际应用中的选择标准是什么?
A1: 主要看应用场景的需求,如果需要实时处理或快速迭代,优先选择Spark;对于大规模的批量处理,MapReduce可能是更经济的选择。
Q2: 使用华为云MRS服务有什么明显的优势?
A2: MRS提供了一站式的企业级大数据集群服务,简化了硬件管理和维护工作,同时具备强大的兼容性和安全性,能够有效降低企业的运营成本。
Spark与MapReduce各自有其优势和适用场景,而华为云MapReduce服务(MRS)为用户提供了一个高效、便捷的大数据处理平台,根据具体的业务需求和预算,可以选择最合适的数据处理方案和服务。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/588359.html
 微信扫一扫
微信扫一扫