

MapReduce基本原理

MapReduce是一个编程模型,用于大规模数据集(大于1TB)的并行运算,该模型主要包括两个函数:Map和Reduce,在分布式计算环境中处理数据,小编将详细探讨其概念、架构、执行过程及优化方法。
概念与计算模型
1、基本概念
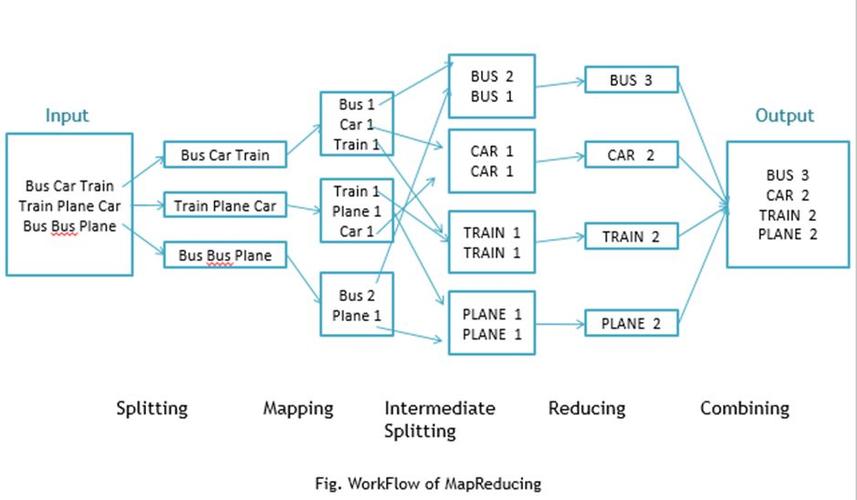
Map: Map是把一组数据对转换为另一组数据对,从而映射出键值对。
Reduce: Reduce关注的是键值对,通过合适的方式合并,得到更小的数据集合。
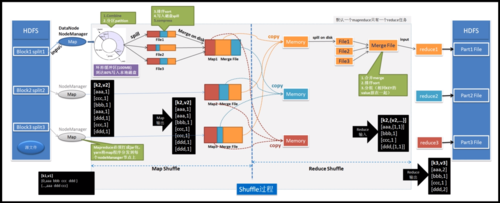
2、计算模型
输入数据: 框架自动分割为多个数据块,输入给Map函数。
输出数据: 经过Map和Reduce函数处理后,最终生成结果文件。
3、数据流
Shuffle: Map输出的数据,需经过Shuffle过程,即排序、传输等,才能作为Reduce的输入。
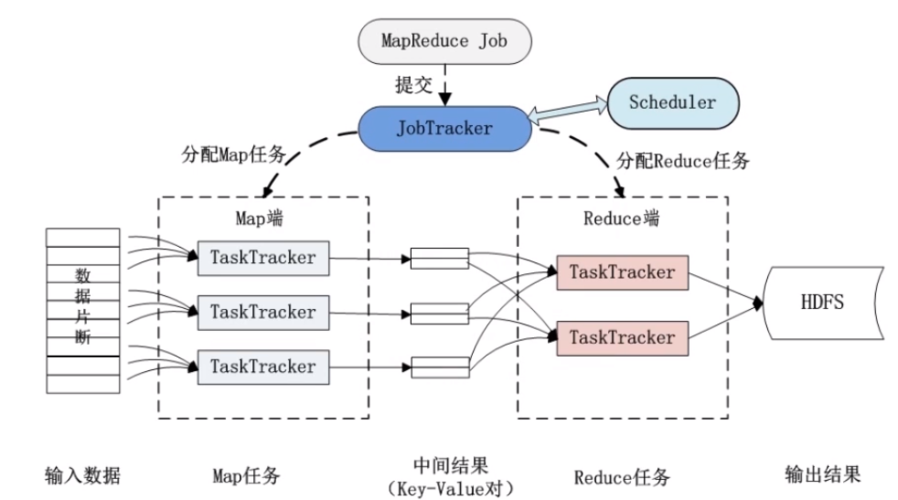
架构与执行流程
1、Mapper
输入: 从HDFS读取数据分片。
处理: 解析每个数据分片,转换成键值对。
输出: 输出中间键值对,准备进行Shuffle。
2、Shuffle and Sort
过程: 对Mapper的输出进行分区、排序、合并,以优化数据传输。
目的: 确保Reducer能接收到正确的数据。
3、Reducer
输入: 从不同Mapper接收数据。
处理: 对具有相同键的值进行合并操作。
输出: 最终结果写回HDFS。
核心组件与任务调度
1、核心组件
JobTracker: 负责资源管理和任务调度。
TaskTracker: 执行具体任务,同时向JobTracker报告状态。
2、任务调度
数据局部性优化: 尽可能将计算任务分配到数据所在的节点,以减少数据传输。
错误处理: 失败任务重试机制,确保高容错性。
性能优化最佳实践
1、参数设置
合理分区: 通过调整分区数,平衡Reducer的负载。
内存配置: 根据数据量和任务复杂度调整JVM堆大小。
2、代码优化
避免数据倾斜: 设计合理的键值对,避免某些Reducer过载。
压缩大对象: 使用压缩技术减少数据传输量。
相关问题与解答
Q1: MapReduce适用于哪些场景?
A1: MapReduce适用于需要处理大规模数据集的场景,如日志分析、大数据处理、机器学习数据预处理等。
Q2: 如何提高MapReduce作业的性能?
A2: 可以通过合理分区、调整内存配置、避免数据倾斜和压缩大对象等方法来提高MapReduce作业的性能。
通过以上详细解析,我们了解了MapReduce的基本原理、架构、执行流程以及优化方法,希望这些信息能帮助开发者和学习者更好地掌握MapReduce,并在实际应用中发挥其强大功能。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/588489.html
 微信扫一扫
微信扫一扫