

MapReduce架构:产品架构

MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,概念“Map(映射)”和“Reduce(归约)”是它们的主要思想,因此它被命名为MapReduce,现实中,很多任务都可以用这种模型来表达。
EMapReduce (EMR) 产品架构
EMapReduce(简称EMR)的产品架构可以细分为以下几个部分:
社区开源产品
EMR集成了Apache社区的开源大数据组件,例如Hadoop、Hive和HBase,这些开源软件随着EMR版本的更新也会相应的升级,不过,已经创建好的EMR集群不支持组件升级。
EMR开源优化
基于开源社区版本的组件,EMR增强了其性能和功能,Delta Lake相较开源版本增加了ZOrder和Data Skipping能力。
EMR自研能力
为了让开源大数据组件和服务更好的运行在阿里云技术设施上,EMR自研了一些组件。
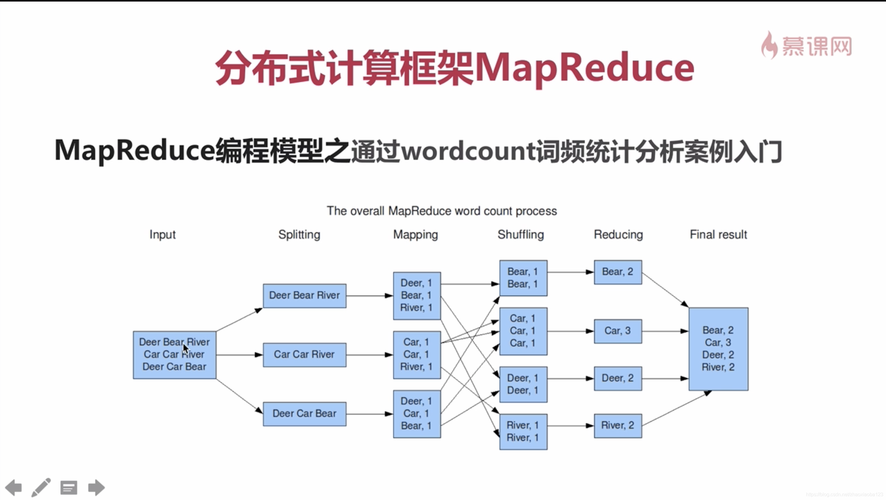
MapReduce流程
MapReduce流程可以分为四个步骤,即input、mapper、reduce和output,数据读取组件从hdfs中读取文件,然后mapper根据读取过来的数据进行数据映射,之后进行混洗,混洗主要进行分区、排序和合并,混洗好的数据交给Reduce步骤进行计算,Reduce计算好的数据经过TextOutputFormat和LineRecordWriter组件,输出到对应OutPutPath中。
腾讯云弹性 MapReduce 产品逻辑架构
EMR主要由开源组件、腾讯云基础设施和集群管理三部分构成,开源组件包括Apache社区的Hadoop、Hive、Spark、Hbase、Presto、Flink、Alluxio、Iceberg等几十种丰富、前沿的开源大数据组件。
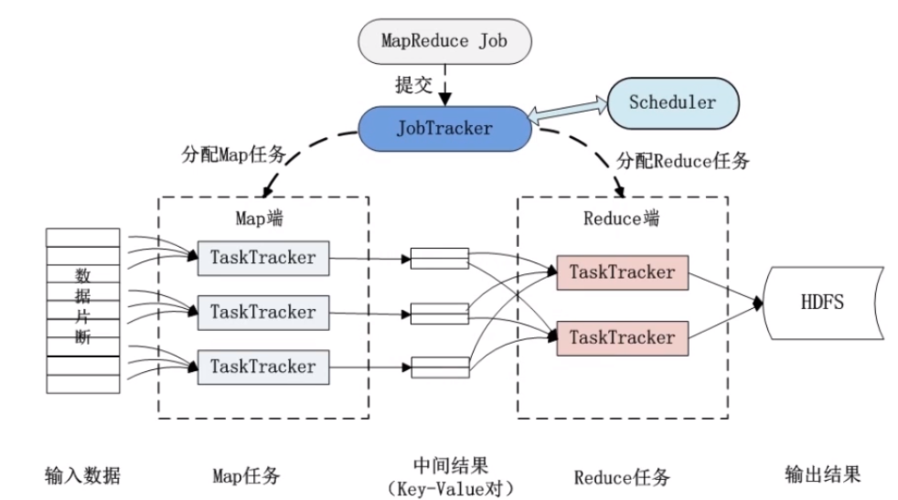
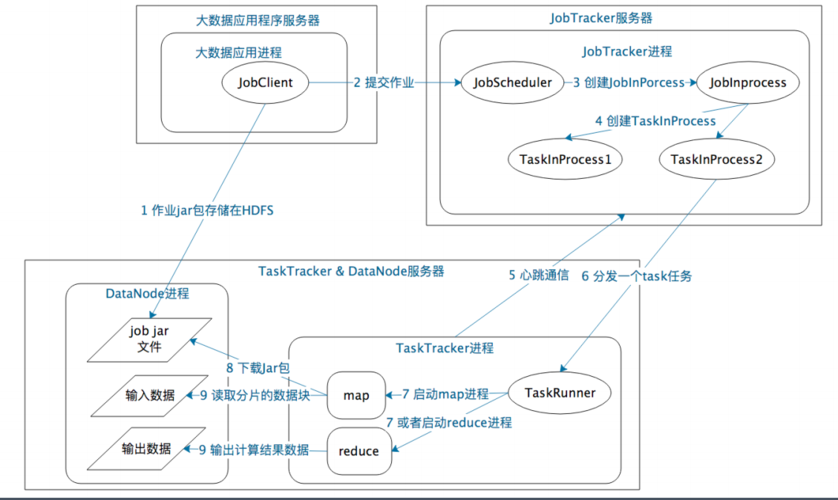
MapReduce的体系结构
MapReduce的体系结构主要由四个部分组成,分别是:Client、JobTracker、TaskTracker以及Task,Client负责提交作业,查看作业运行状态;JobTracker监控资源、调度作业,监控所有的TT和Job的健康;TaskTracker向JT汇报资源使用情况和作业运行情况,接受JT的命令并执行;Task分为Map Task和Reduce Task两种,均由TaskTracker启动。
开源大数据开发平台EMapReduce (EMR)
EMapReduce(简称EMR)是运行在阿里云平台上的一种大数据处理系统解决方案,EMR基于开源的Apache Hadoop和Apache Spark,让用户可以方便地使用Hadoop和Spark生态系统中的其他周边系统分析和处理数据。
相关问题与解答
问题1: EMR支持哪些开源组件?
答案: EMR集成了Apache社区的开源大数据组件,例如Hadoop、Hive和HBase等。
问题2: MapReduce的工作流程是怎样的?
答案: MapReduce的工作流程主要包括数据读取、映射(Mapping)、混洗(Shuffling)和归约(Reducing)四个步骤。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/588571.html
 微信扫一扫
微信扫一扫