

贝叶斯算法的基础上, 结合 MapReduce 并行计算框架的优势, 提出了一种朴素贝叶斯算法的并行化实现方案。

安装准备
安装准备是确保实验环境正确搭建的首要步骤,需要特别注意选择合适的操作系统和工具版本。
系统与软件配置
VMware安装:使用VMware虚拟机安装Ubuntu操作系统,为后续的Hadoop环境搭建提供基础。
Hadoop环境:在Ubuntu上安装Hadoop 2.7.7版本,这是实现MapReduce的基础框架。
软件选择依据:选择适合的操作系统(如Ubuntu)和软件版本(如Hadoop 2.7.7),以确保兼容性和操作的便捷性。
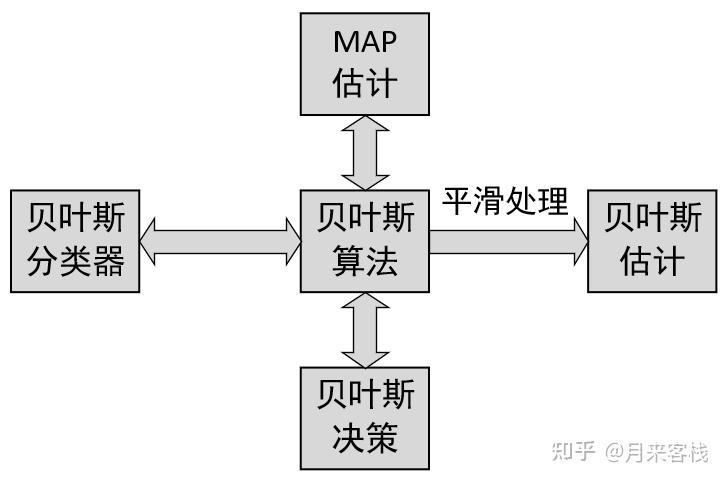
朴素贝叶斯分类
朴素贝叶斯分类是一种基于贝叶斯定理的概率分类器,通过属性集合来实现对象的分类。
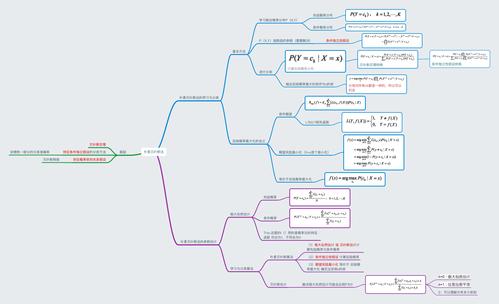
朴素贝叶斯理论基础
贝叶斯定理应用:通过贝叶斯定理计算在给定其他属性的情况下,一个类别的概率。
独立假设:朴素贝叶斯分类器假设各属性之间相互独立,这简化了概率计算的过程。
分类预测:利用已知概率模型,对新的未知数据进行分类预测。
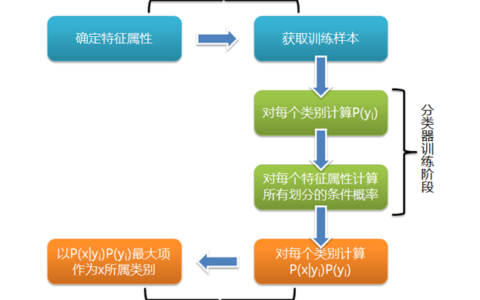
MapReduce实现朴素贝叶斯
MapReduce模型能够有效处理大规模数据集,将计算任务分发到多个节点并行处理。
数据准备
输入数据格式:通常为符号数据,每条记录包含条件属性和类别属性。
训练数据集:通过大量已分类的数据来训练模型,以获取各个属性对应的类别概率。
并行计算过程
Map阶段:将数据集拆分成多个小数据集,每个节点分别计算本地数据的局部概率。
Reduce阶段:汇总所有节点的局部概率,生成全局概率模型。
朴素贝叶斯算法公式
朴素贝叶斯算法公式是实现分类的核心,根据已有的属性判断分类的可能性。
概率计算
先验概率:计算每个类别的先验概率,即该类别在训练集中出现的频率。
后验概率:结合先验概率和似然概率,通过贝叶斯公式计算得到后验概率。
模型应用
属性独立性:应用独立假设,简化似然概率的计算过程。
分类决策:根据后验概率的大小,确定数据点最可能属于的类别。
朴素贝叶斯算法优势与挑战
朴素贝叶斯算法因其简单和效率而被广泛应用,但也存在一些限制。
算法优点
高效性:算法简单,数据处理速度快,特别适合处理大规模数据集。
易于实现:模型结构简单,实现起来比较方便。
面临挑战
属性独立性假设:现实中属性间可能存在依赖关系,这可能会影响分类的准确性。
数据稀疏问题:在数据稀疏的情况下,概率估计可能会有较大偏差。
相关问题与解答
对于深入理解朴素贝叶斯分类及其在MapReduce上的实现,以下问题及解答可能会有所帮助。
Q1: 如何处理属性间的依赖关系?
A1: 可以通过使用贝叶斯网络替代朴素贝叶斯分类器来处理属性间的依赖关系,贝叶斯网络能够表示属性间的概率依赖关系,从而提供更准确的分类。
Q2: 如何评估朴素贝叶斯分类的性能?
A2: 通常采用交叉验证的方法来评估分类性能,将数据集分为训练集和测试集,通过训练集建立模型,然后在测试集上评估模型的准确率、召回率等指标。
归纳朴素贝叶斯分类与MapReduce的结合,不仅提高了处理大规模数据的能力,还为解决实际分类问题提供了有效的方法,了解其理论与实践,有助于在实际项目中更好地应用这一技术。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/588675.html
 微信扫一扫
微信扫一扫