

MapReduce编程模型适合用于大规模数据集的并行处理,小编将详细探讨MapReduce的核心概念、组成部分以及与其他组件的关系,通过小标题和单元表格的形式进行结构化呈现,并在最后提供相关问题与解答栏目。
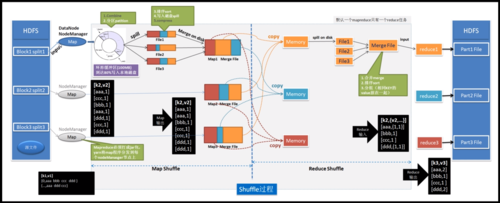

MapReduce的核心概念
1、映射(Map)
功能描述:映射阶段接受原始数据输入,并转换为键值对输出。
数据处理:每个Mapper任务处理数据的一个小片断,生成中间键值对。
并行性:多个Mapper可以并行执行,提高处理速度。
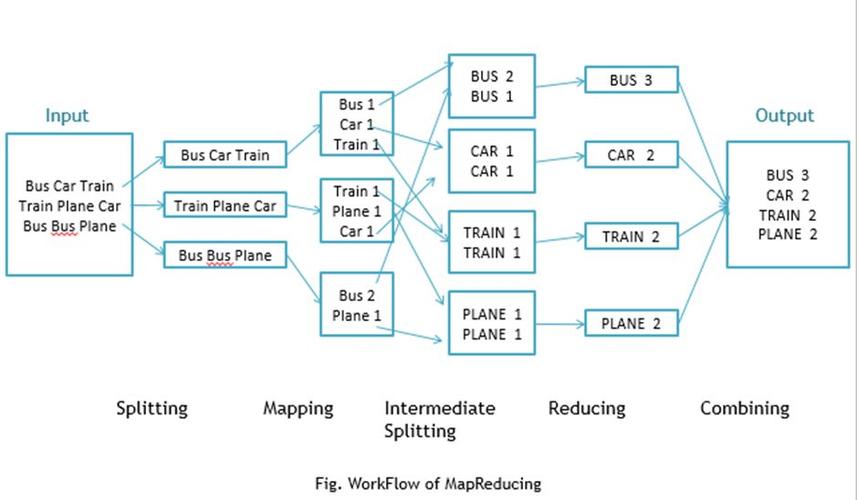
2、归约(Reduce)
功能描述:归约阶段接受Map阶段的输出键值对,并根据键进行汇总。
结果输出:每个Reducer任务处理特定键的所有值,生成最终结果。
汇总方式:Reducer将相同键的值进行汇总,如计算总和、平均值等。
3、分布式存储
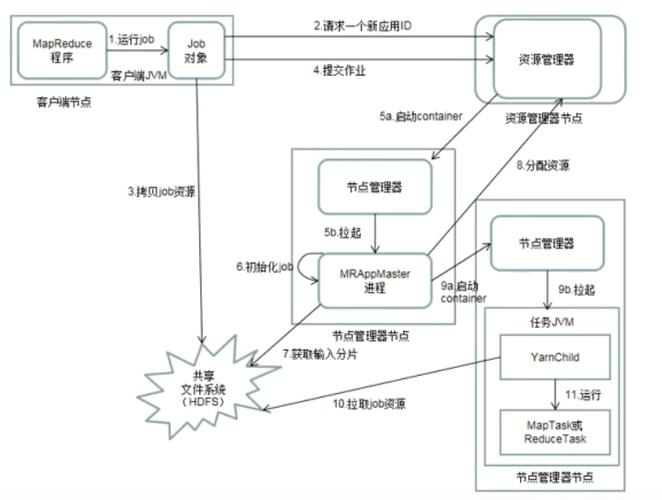
存储系统:通常结合如HDFS的分布式文件系统来存储数据。
数据可靠性:分布式存储提高了数据的可靠性和容错能力。
优化访问:数据本地化优化,将计算任务调度到数据所在节点,减少网络传输。
4、性能优化
任务粒度:合理设置Map和Reduce任务的数量,可以优化程序性能。
资源管理:高效的资源管理机制(如YARN)确保资源的有效利用。
缓存机制:使用缓存可以减少重复计算,提高处理效率。
5、扩展性和灵活性
水平扩展:可以通过增加节点来扩展系统处理能力。
编程抽象:MapReduce提供了简单的编程模型,易于学习和实现。
适用场景:适用于数据密集型和计算密集型任务。
MapReduce与其他组件的关系
1、与HDFS的关系
数据存储:HDFS为MapReduce提供高吞吐量的数据访问。
容错性:HDFS的高容错性支持MapReduce在硬件故障时的数据安全。
数据本地化:MapReduce尽量在数据所在的节点上运行任务,以减少数据传输开销。
2、与YARN的关系
资源管理:YARN负责管理MapReduce作业的资源分配和调度。
任务监控:YARN监控MapReduce任务的运行状态,确保作业稳定运行。
性能优化:YARN的引入提高了MapReduce作业的执行效率和资源利用率。
3、与其他数据处理组件的关系
数据流处理:可以与Spark等实时处理框架结合,实现不同类型数据处理。
数据仓库应用:与Hive等数据仓库工具结合,支持复杂的数据分析操作。
数据存储系统:与HBase等NoSQL数据库集成,提供大规模的数据存储和查询功能。
针对本文内容,提出两个相关问题并做出解答。
相关问题与解答
Q1: MapReduce如何处理数据倾斜问题?
A1: 数据倾斜是MapReduce中一个常见问题,指的是某些键的值比其他键多很多,导致处理时间延长,解决这一问题的策略包括:使用更均匀的键分布、在Map阶段进行局部聚合以减少数据传输、在Reduce阶段使用组合技术如MapJoin或者在Reduce之前进行一个额外的聚合阶段,一些更高级的处理模型如Apache Spark提供了更好的处理机制来应对数据倾斜问题。
Q2: MapReduce如何保证数据处理的可靠性?
A2: MapReduce通过多种机制保证数据处理的可靠性,它依赖于分布式文件系统(如HDFS)来存储数据,该系统已经具备数据块复制机制来防止硬件故障导致的数据丢失,MapReduce任务在失败时会自动重新执行,无需人工干预,系统会周期性地检查任务的进度和节点的健康状态,确保作业能够顺利完成,这些机制共同作用,使得MapReduce能够在面对大规模数据集时提供高可靠性的数据处理服务。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/588771.html
 微信扫一扫
微信扫一扫