


在大数据时代,数据挖掘与分析变得日益重要,聚类作为数据分析的常见手段之一,被广泛应用于模式识别、机器学习等多个领域,MapReduce是一种编程模型,适用于大规模数据集的并行处理,将聚类算法部署在MapReduce框架下,可以有效提高处理海量数据的能力。
算法原理
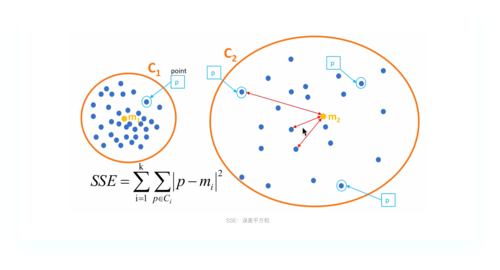
Kmeans聚类基础
定义:Kmeans是一个基于距离的聚类算法,旨在将数据集中的对象划分为K个簇,使得同一簇内的对象相似度高,不同簇之间的相似度低。
应用场景:例如市场营销中根据消费者购买行为进行分群,或在文档分类中根据内容相似性分组等。
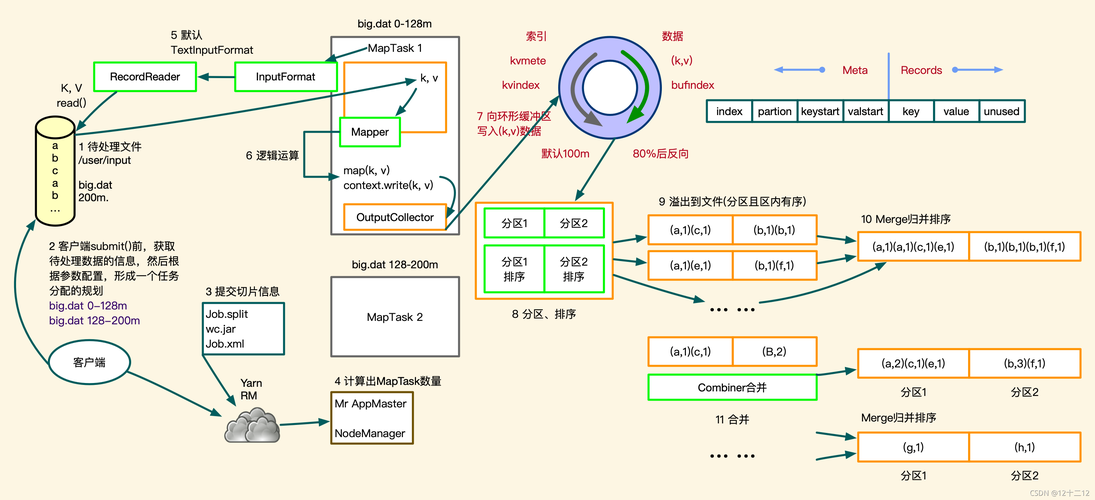
MapReduce框架
概念:MapReduce是一个编程模型,用户只需编写Map和Reduce两个函数即可实现并行化计算,非常适合于海量数据的处理。
优势:通过分布式计算资源,可以显著提高数据处理的速度和效率。
结合方式
并行化:通过将Kmeans算法的迭代过程分解为多个子任务,并分配到不同的计算节点上,可以加快算法的运行速度。
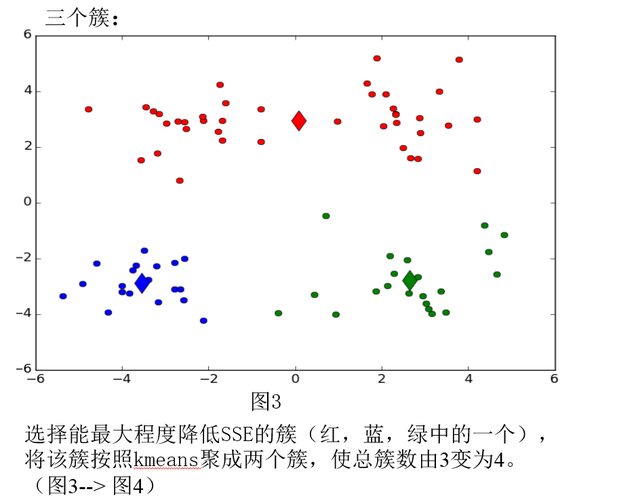
优化策略:利用改进的相异度函数确定K值和初始聚类中心,以及采用Canopy算法预聚类,降低计算规模。
算法流程
初始化阶段
选择K值:根据数据的相异程度动态确定K值,选取相异度较小的点作为初始聚类中心。
并行计算
Map阶段:每个Map任务负责部分数据点的归属计算,将其映射到相应的簇。
Reduce阶段:汇总各Map任务的结果,更新簇中心,并判断是否达到结束条件。
优化策略
Canopy算法:粗略聚类,用于估算K值并优化初始聚类中心。
密度与距离法:结合系统抽样方法得到代表性样本集,优化初始聚类中心的选择。
关键特性与优势
加速比
线性增长:随着计算节点的增加,改进后的Kmeans算法能够实现接近线性的加速比。
准确率与收敛时间
提升效果:基于MapReduce的Kmeans算法相比传统算法,在准确率和收敛时间方面都有所提高。
扩展性
数据规模:并行聚类模型能适应不同规模的数据量,保持良好性能。
实验结果
算法对比
MRCoMatrix与MRStatistics:应用知识文献统计算法,在网络文献知识库的聚类和统计上取得理想效果。
性能评估
并行化效果:改进后的Kmeans算法在处理大数据集时表现出良好的性能。
相关问题与解答
MapReduce如何优化Kmeans算法?
MapReduce通过分布式计算优化了Kmeans算法的处理速度,特别是在大数据环境下,通过并行计算显著提高了算法的效率。
Kmeans算法在MapReduce框架下的扩展性如何?
在MapReduce框架下的Kmeans算法显示出良好的扩展性,无论是增加计算节点还是数据规模扩大,都能保持良好的性能表现。
基于MapReduce的聚类系数算法(特别是Kmeans)不仅提升了数据处理的速度和质量,而且增强了处理大规模数据集的能力,这种结合了先进编程模型和经典算法的方法,为现代大数据分析和数据挖掘领域带来了新的机遇,随着技术的不断发展,未来还会有更多的优化和创新,进一步推动这一领域的发展。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/588816.html
 微信扫一扫
微信扫一扫