

关联分析是数据挖掘领域的一个重要分支,用于发现大规模数据集中的有趣关系,MapReduce是一种编程模型,它为处理大规模数据集提供了一个高效的框架,在MapReduce环境下进行关联分析,可以有效地处理和分析大型数据集,小编将详细探讨MapReduce关联分析的相关知识。
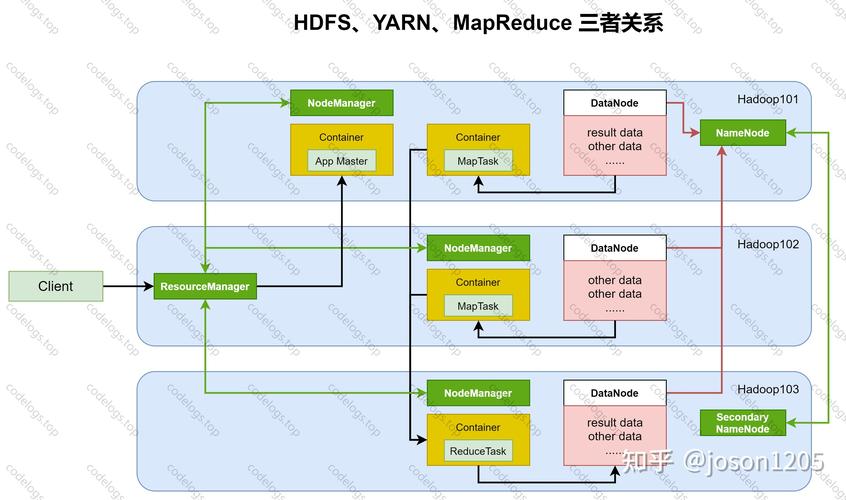

MapReduce关联分析基础
MapReduce概念
MapReduce是一个编程模型,它包括两个主要阶段:Map阶段和Reduce阶段,在Map阶段,系统会将输入数据分成多个独立的数据块,每个数据块由一个Map任务处理,在Reduce阶段,所有Map任务的输出结果将被整合,以生成最终的结果。
关联分析定义
关联分析旨在发现数据集中项之间的有意义的关系,这些关系通常表现为频繁出现的项集,顾客经常一起购买的商品组合,通过分析这些模式,企业可以优化商品布局、促销策略等。
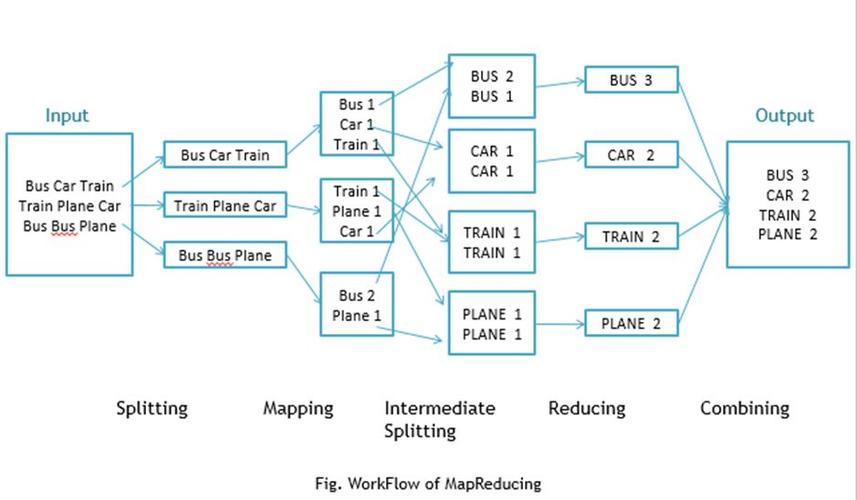
MapReduce关联分析实现
MapReduce Join技术
MapReduce Join是一种将两个或多个数据集关联起来的技术,在MapReduce环境中,通过将待关联的数据集按相同的关键字分组,然后由Reduce任务处理同一组内的数据,从而实现数据的关联操作。
Hadoop平台应用
Hadoop是一个开源的MapReduce实现,它提供了分布式文件系统HDFS来存储大规模数据集,并且可以将算法的输入和输出转换成MapReduce计算模型要求的〈key, value〉对格式。
Apriori算法改进
Apriori算法是一种经典的关联规则挖掘算法,其主要思想是通过迭代方法产生频繁项集,在MapReduce环境下,可以通过改进Apriori算法来高效地处理大规模数据集的关联分析。
关联分析对象
数据集
数据集是关联分析的对象之一,它可以是商业交易记录、购物篮数据等,数据集的规模往往很大,包含成千上万甚至更多的记录。
项集
项集是指数据集中的相关项目的组合,在关联分析中,目标是找出频繁出现的项集,它们表明了不同项目之间存在某种关联。
关联分析的重要性与应用
市场篮分析
通过关联分析,可以发现顾客购物篮中商品之间的关联规则,帮助企业了解哪些商品经常一起被购买,从而优化商品推荐和库存管理。
推荐系统
关联分析在推荐系统中扮演重要角色,通过分析用户的历史行为数据,可以发现用户兴趣之间的关联,为用户提供个性化的推荐内容。
相关问题与解答
Q1: 使用MapReduce进行关联分析的优势是什么?
A1: 使用MapReduce进行关联分析的主要优势在于其能够高效处理大规模数据集,通过分布式计算,MapReduce可以在多台计算机上并行处理数据,显著减少了数据处理时间,MapReduce简化了并行程序的设计和实现,使得开发者可以专注于算法逻辑而不是并行化的细节。
Q2: MapReduce在处理关联分析时有哪些挑战?
A2: 尽管MapReduce为处理大规模数据集提供了强大的工具,但在处理关联分析时也面临一些挑战,数据分布不均可能导致某些节点过载,影响整体性能,对于需要多次迭代的算法(如Apriori算法),MapReduce可能需要执行多个MapReduce作业,增加了处理时间,MapReduce模型在处理具有复杂依赖关系的任务时可能不够灵活。
提供了关于MapReduce关联分析的基础知识、实现方法、重要性与应用以及相关问题与解答的全面,通过这些信息,用户可以更好地理解如何在MapReduce环境下进行有效的关联分析。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/588864.html
 微信扫一扫
微信扫一扫