


MapReduce数据处理流程详解
1. 数据准备阶段
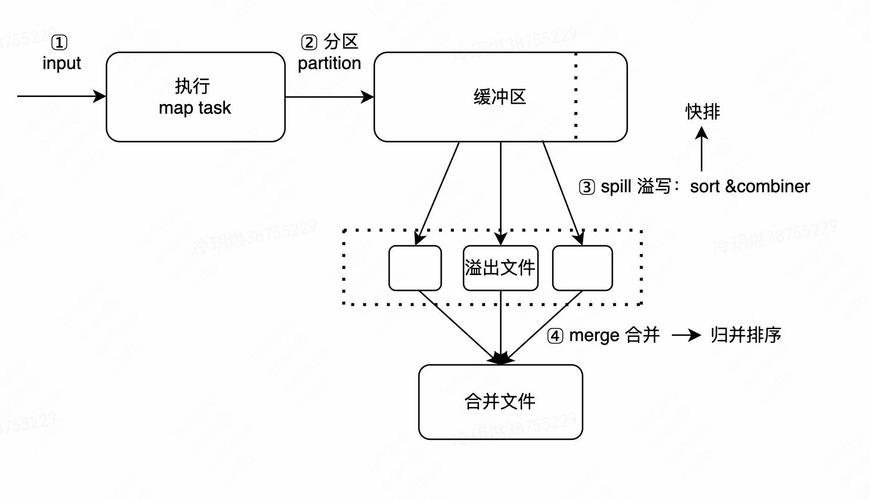
分片操作(Sharding):在处理大数据时首先需要将数据源分片成多个小块,每个块默认大小为128MB(在Hadoop 2.x中),这一步是为了让不同的Map任务能并行处理数据。
格式化操作:分片后的数据需转换为键值对形式<key, value>,key通常代表数据的偏移量,value则为数据本身的内容。
2. Map阶段
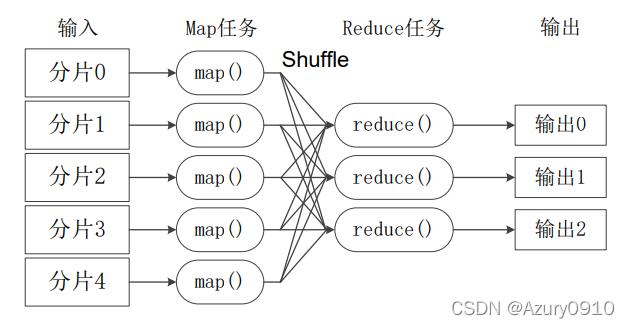
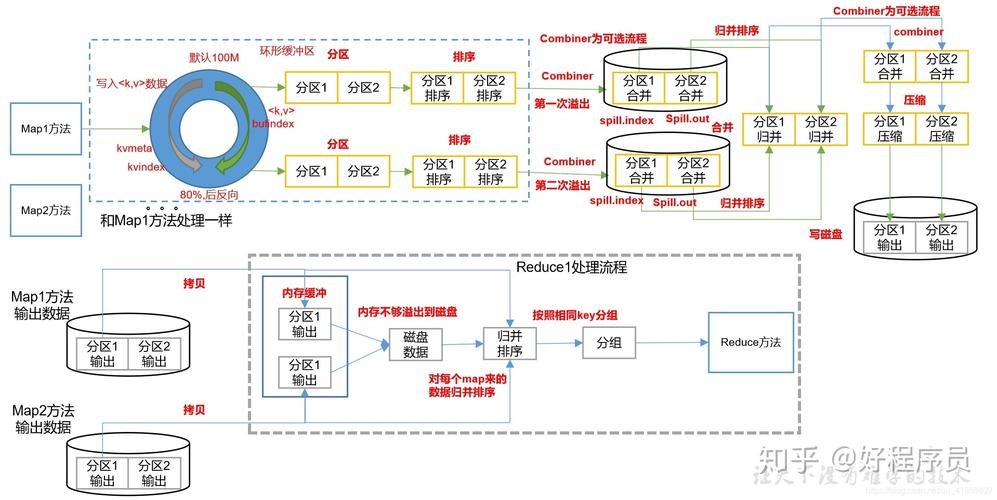
执行MapTask:为每个分片构建一个Map任务,这些任务运行用户自定义的map函数,处理分片内每条记录。
数据排序与合并:Mapper的输出会根据key进行排序,并可能进行局部合并(例如使用Hash分区),以减少数据传输过程中的网络负载。
3. Shuffle阶段
数据重新分区:Map阶段的输出必须重新组织,以确保具有相同key值的所有数据项都传送到同一个Reducer,这一步骤通常包括排序和分组操作。
数据拷贝:处理完的数据被拷贝到执行Reduce任务的节点的缓存中,在此阶段,还可以配置数据压缩和确定Reduce节点的数量。
4. Reduce阶段
最终数据处理:Reducers将接收到的数据进一步进行排序和合并,形成一份完整的文件,然后使用用户定义的Reduce函数按顺序处理这些数据。
5. 输出阶段
结果存储:最终的处理结果通常会写回到文件系统(如HDFS),供其他任务或应用程序使用。
MapReduce应用开发流程
1. 设计阶段
需求分析:明确要处理的数据类型和业务逻辑,决定Map和Reduce函数的主要功能。
技术选型:选择合适的Hadoop版本和其他支持工具,如Hive或Pig等。
2. 实现阶段
编写Map和Reduce函数:根据需求实现具体的Map和Reduce逻辑。
配置和优化:设置合适的MapReduce参数,比如内存大小、并发任务数等,以优化性能。
3. 测试阶段
单元测试:对单独的Map和Reduce函数进行测试,确保其逻辑的正确性。
集成测试:在小规模数据集上运行整个MapReduce作业,检查数据处理的正确性和效率。
4. 部署与监控
部署:将应用部署到生产环境,观察其在大规模数据上的表现。
监控与调优:持续监控应用的运行状态,并根据需要进行调优。
问题与解答
Q1: MapReduce如何处理数据倾斜问题?
A1: 数据倾斜是指不同Key对应的数据量差异极大,导致某些Reducer过载,解决这一问题的方法包括预先对Key进行采样和分析,合理设定Partition策略,或者使用MapReduce之外的框架如Spark进行动态分配资源。
Q2: MapReduce框架如何保证容错性?
A2: MapReduce通过多种机制保证容错性,包括数据备份、自动重启失败的任务和利用Checkpoint记录任务状态,HDFS的副本机制也确保了数据在不同硬件故障下的安全性。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/588916.html
 微信扫一扫
微信扫一扫