

优化MapReduce和Snappy_HIVE的策略
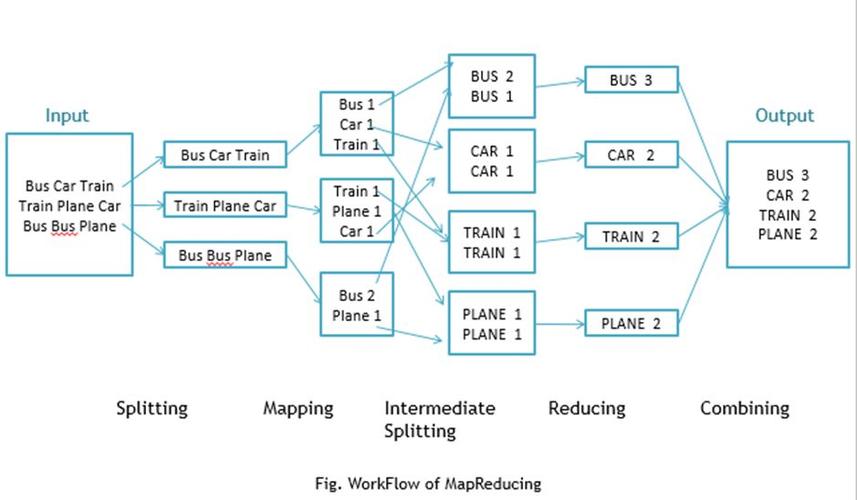

在大数据时代,处理海量数据的能力变得尤为重要,Hive作为一个建立在Hadoop之上的数据仓库工具,通过将SQL查询转换成MapReduce任务处理大规模数据集,为了提高数据处理效率,对MapReduce作业以及Snappy_HIVE的优化显得尤为关键,小编将详细探讨如何针对这两个方面进行性能优化。
内存优化
内存是影响MapReduce性能的重要因素之一,合理配置内存参数可以显著提升作业执行效率。
1. 调整Reduce阶段内存
设置Reduce内存大小:通过set mapreduce.reduce.memory.mb=8192;命令可调整Reduce阶段的内存使用量,此处设置为8192M,相较于默认值1024M有大幅提升。
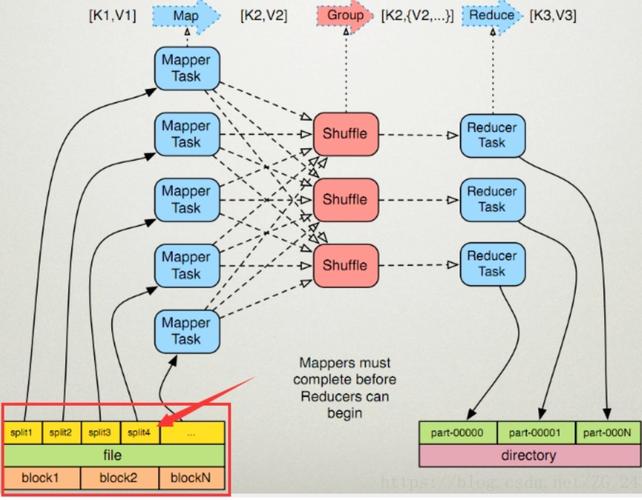
配置JVM内存:set mapreduce.reduce.java.opts=Xmx6144m;用于设置JVM的最大堆内存,一般建议设置为Reduce内存的75%。
2. JVM重用
开启JVM重用:减少JVM启动和停止的开销,可以加速MapReduce作业的执行。
合理配置重用次数:避免因为长时间持有资源导致系统资源浪费。
Hive配置优化
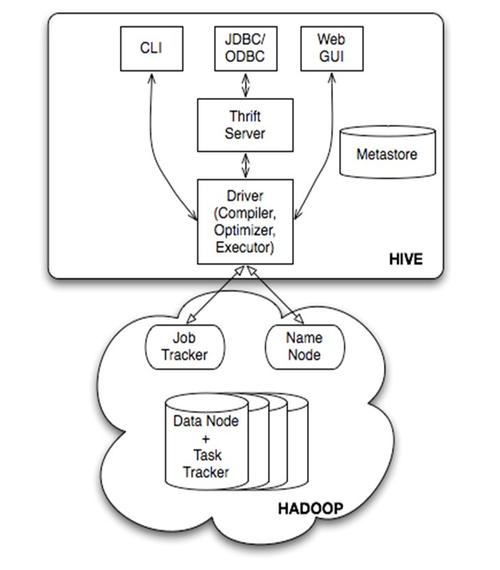
Hive的配置参数直接关系到MapReduce作业的性能,合理的参数设置可以有效避免不必要的性能损耗。
1. 内存和IO优化
调整内存设置:通过增加Hive执行器的内存来提高查询速度。
优化文件缓存:调整hive.thrift.server.cache.size来控制Thrift服务器缓存的大小,提高缓存命中率。
2. 编译器优化
选择适合的编解码器:对于中间数据压缩,应选择低CPU开销的编解码器,以降低CPU负担,加快数据处理速度。
调整压缩参数:通过设置mapred.map.output.compression.codec参数选择合适的压缩方式,平衡压缩率和系统开销。
计算框架选择
除了传统的MapReduce计算框架外,其他框架如Spark和Tez提供了更优的性能表现。
1. 使用Spark
优势对比:Spark提供内存计算能力,相比Hadoop MapReduce有更快的数据处理速度。
集成简易性:Spark可以无缝集成到现有的Hadoop生态系统中,共享Hadoop集群的资源。
2. 使用Tez
优化复杂度:Tez通过优化DAG(有向无环图)减少了MapReduce作业的复杂性,提高了执行效率。
降低延迟:Tez支持更高的资源分配粒度,能够更灵活地管理任务,从而降低作业执行的延迟。
数据存储与处理
数据的存储格式和处理方式直接影响到HiveQL的查询效率。
1. 选择合适的文件格式
优化存储格式:根据数据访问模式选择最合适的文件格式,如Parquet和ORC等列式存储格式,可以提升查询性能。
数据分区:合理的数据分区可以大幅减少数据扫描的范围,提高查询效率。
2. SQL层面优化
优化HiveQL语句:避免全表扫描和复杂的Join操作,尽可能使用分区过滤和列剪枝来减少处理的数据量。
使用分桶表:分桶表可以进一步提高查询性能,特别是在进行大范围的数据聚合时。
在优化MapReduce和Snappy_HIVE的过程中,需要综合考量硬件资源、软件配置、计算框架及数据处理方式等多方面因素,通过细致的调优,可以显著提升数据处理的速度和效率,满足业务需求,优化是一个持续的过程,需要根据实际情况不断调整策略,以达到最佳的性能表现。
相关问题与解答
Q1: 如何进一步优化Hive查询?
A1: 除了上述提到的优化措施,还可以考虑以下方法:使用向量化的查询执行来提高数据处理速度;启用Hive的统计信息收集功能,以便优化执行计划;定期维护和清理数据,避免数据碎片化。
Q2: 是否有必要将所有作业迁移到Spark或Tez?
A2: 并不是所有作业都适合迁移到Spark或Tez,应根据作业的具体需求和现有资源情况来决定,对于某些重计算轻IO的任务,Spark可能更有优势;而对于IO密集型任务,Tez可能更适合,评估迁移的成本与收益是关键。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/589004.html
 微信扫一扫
微信扫一扫