

MapReduce图解服务

MapReduce是由谷歌提出并广泛使用在Hadoop生态系统中的一个分布式计算框架,它允许大规模数据集在集群中的并行处理,该框架通过两个主要的函数:Map和Reduce,对数据进行处理和归纳。
MapReduce核心组成
Map阶段: Map负责数据的过滤和转换,输入数据被分成小块,每块数据由一个Map任务处理,每个Map任务生成键值对,作为中间结果输出。
Reduce阶段: Reduce负责将Map阶段的输出根据键进行合并,以生成最终的结果,所有共享同一键的值会被发送到同一个Reduce任务。
MapReduce工作流程
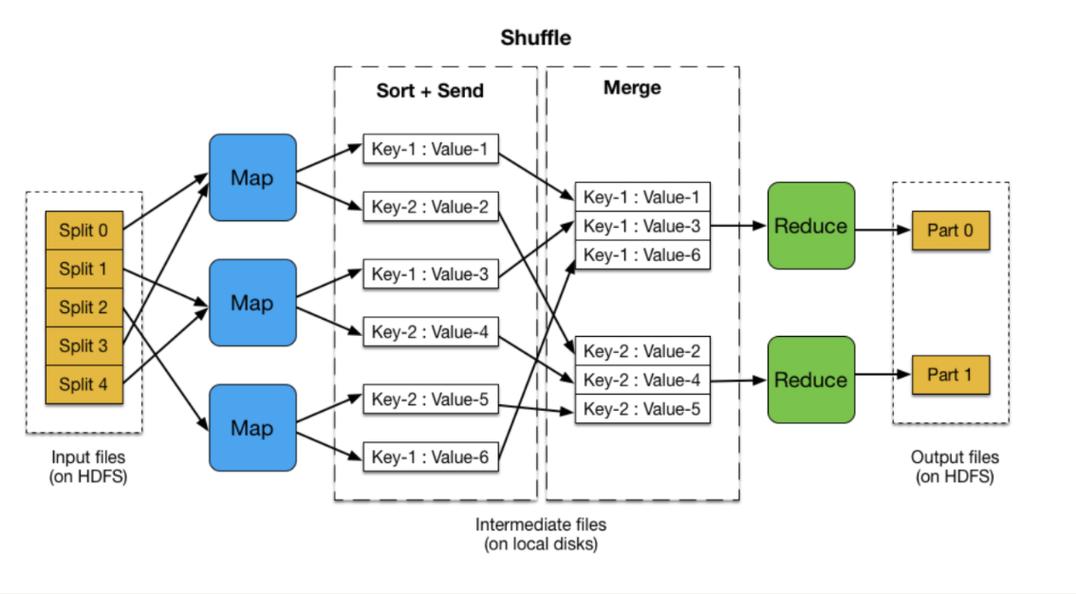
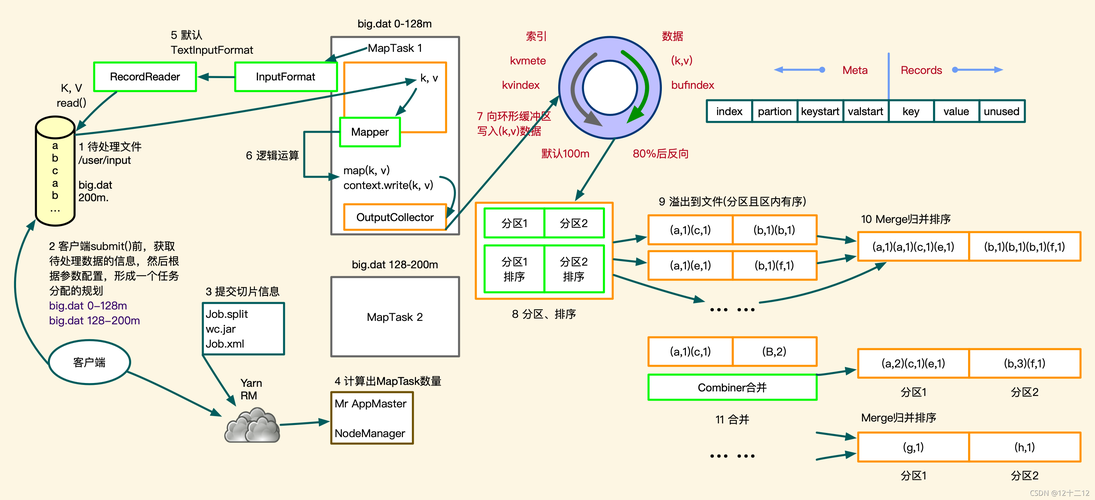
下面是MapReduce的详细工作流程图解:
1、数据读取
从HDFS中读取文件。
使用TextInputFormat和LineRecordReader等组件辅助数据读取。
2、数据分片
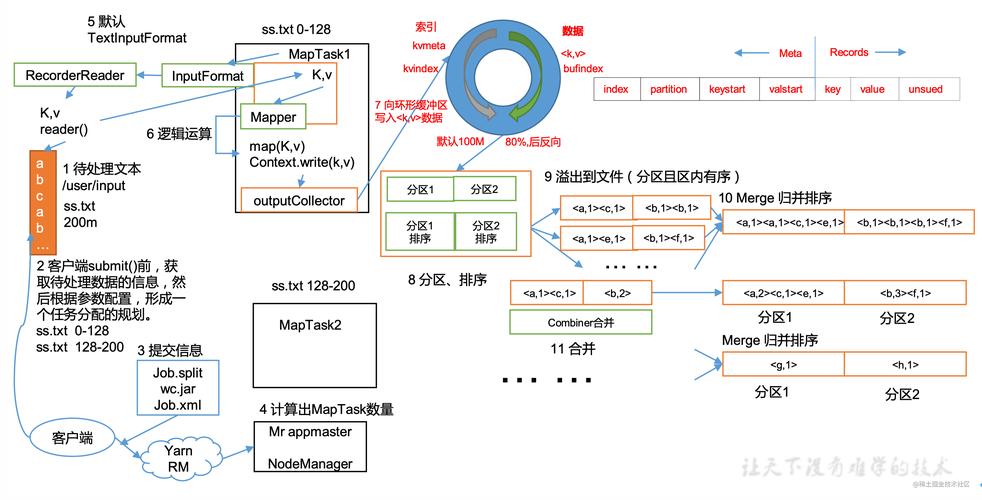
数据通过InputFormat被切分成小的Split。
每个Split生成一个MapTask进行处理。
3、Mapper
对每个分片中的数据执行Map函数。
输出中间键值对。
4、Shuffle
重新排序并分区数据。
将数据从各个MapTask拷贝到对应的Reduce节点。
5、Reduce
对缓存中的数据进一步排序和merge。
执行Reduce函数生成最终结果。
设计思想与优缺点
设计思想: Hadoop MapReduce的设计思想主要源自于简化编程接口和提高系统容错性的需要,其目的是处理搜索引擎面临的海量数据处理和扩展性问题。
优点: 包括易于编程、高容错性和可扩展性,用户只需要实现简单的函数即可实现复杂的分布式程序。
相关问题与解答
Q1: MapReduce适用于哪些场景?
A1: MapReduce特别适用于需要处理大量非结构化或半结构化数据的场景,如日志分析、大数据处理、Web索引等。
Q2: MapReduce存在哪些局限性?
A2: MapReduce的主要局限性包括处理实时数据的能力较弱,以及不适合需要进行多次迭代的算法,因为每次迭代都会读写HDFS,增加了额外的开销。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/589272.html
 微信扫一扫
微信扫一扫