

MapReduce是一种在大规模数据集上执行分布式计算的编程模型,常用于进行数据密集型任务的处理,在文本分析领域,分词作为信息提取的重要步骤,经常与MapReduce结合使用以提升处理效率,本文将深入探讨如何利用MapReduce进行分词操作。

MapReduce
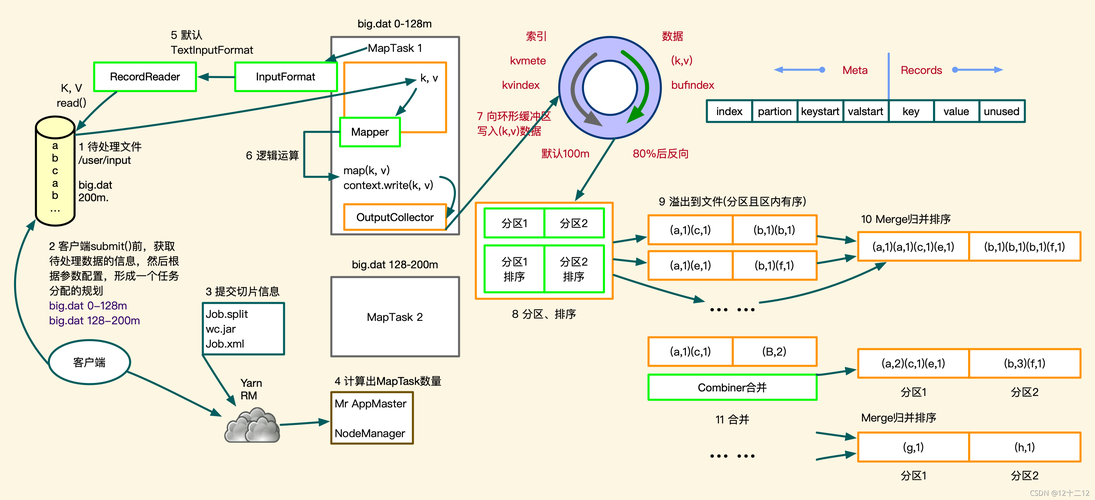
Hadoop MapReduce是一个基于Java的分布式计算框架,它允许开发者编写和运行并行计算任务,从而有效地处理大量数据,该模型主要包含两个阶段:Map阶段和Reduce阶段,在Map阶段,系统会将输入数据分成多个独立的数据块,Map任务分别处理这些块并生成中间结果;在Reduce阶段,这些中间结果被整合得到最终结果。
分词原理
分词是将连续文本分割成有意义的单元(如单词或词语)的过程,在MapReduce中,这一过程通常发生在Map阶段,通过编写自定义的Map函数,可以实现对输入文本数据的分词处理,可以使用Python的jieba库或Java的hanLP库来辅助完成中文分词任务。
分词实现
在MapReduce中实现分词涉及几个关键步骤,需要准备分词库或词典文件,这通常是提高分词准确性的关键,在Map阶段读取文本数据并应用分词算法将其分割成单独的词汇单元,在Reduce阶段可以对这些分词结果进行统计或其他形式的处理。
案例应用
单词计数是MapReduce分词的一个经典案例,在该例子中,Map函数负责读取文本并分词,然后输出每个单词及其出现次数;Reduce函数则对所有相同单词的出现次数进行汇总,最终得出每个单词的总出现次数。
技术挑战
尽管MapReduce在处理大规模数据集方面具有显著优势,但在实际应用中也面临一些技术挑战,对于复杂的分词需求,简单的MapReduce模型可能难以满足性能和准确性的双重要求,分词的准确性高度依赖于所选分词库的质量和适用性。
未来展望
随着人工智能技术的不断发展,未来可能会出现更多智能化的分词工具,这些工具能够更好地理解文本内容,提供更为准确的分词服务,随着计算能力的增强,MapReduce模型本身也可能得到进一步优化,以更高效地支持复杂文本处理任务。
相关问题与解答
1、问:如何在Hadoop上实现自定义词典的中文分词?
答:可以通过集成类似hanLP这样的中文处理库到Hadoop Streaming中,然后在Map函数中调用这些库提供的API来实现基于自定义词典的中文分词。
2、问:MapReduce分词过程中如何处理多语言混合文本?
答:处理多语言混合文本时,MapReduce程序需要能够识别并应用多种语言的分词规则,可以在Map阶段根据语言特性加载不同的分词库,实现对不同语言部分的正确分词。
利用MapReduce进行分词不仅提高了处理大规模文本数据的效率,也展示了分布式计算在自然语言处理领域的应用潜力,通过不断优化算法和扩展分词库,可以进一步提升分词任务的性能和精确度。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/589276.html
 微信扫一扫
微信扫一扫