

MapReduce 合并_合并段
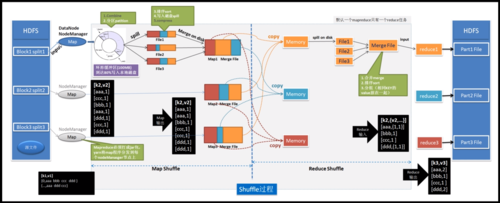

MapReduce是一种编程模型,用于处理和生成大数据集的并行计算,在MapReduce中,数据被分成多个独立的块(分片),每个块由一个Map任务处理,然后结果被Reduce任务合并,小编将详细介绍MapReduce中的合并过程。
Map阶段
1、输入: 原始数据被分割成多个独立的块,每个块包含一部分数据。
2、映射函数: 对每个数据块应用映射函数,生成一组键值对。
3、输出: 映射函数的结果作为中间输出,通常存储在本地磁盘上。
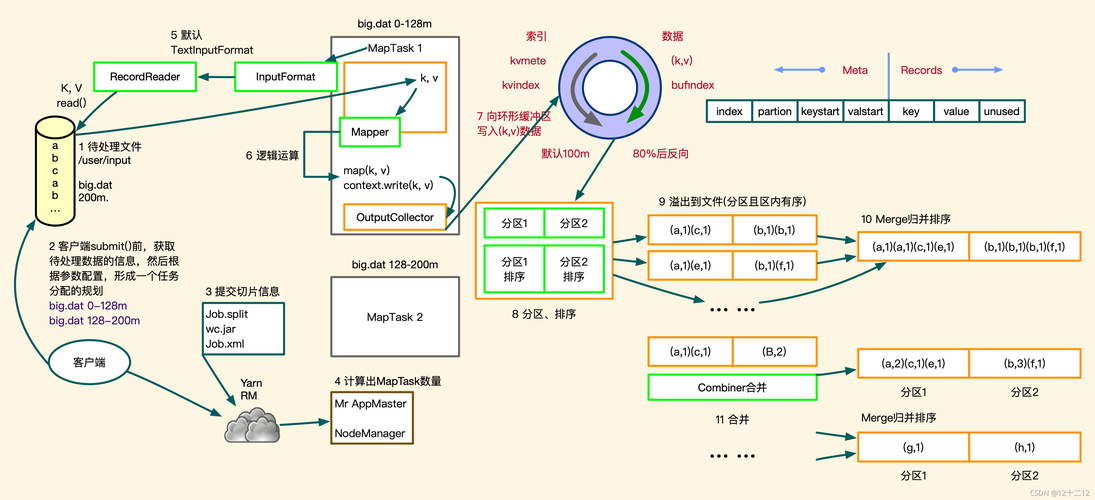
Shuffle阶段
1、排序: 将所有Mapper的输出按键进行排序,确保具有相同键的所有值都在一起。
2、分区: 根据键的哈希值或范围,将排序后的键值对分配给不同的Reducer。
3、合并: 对于每个Reducer,将从不同Mapper接收到的具有相同键的值合并成一个列表。
Reduce阶段
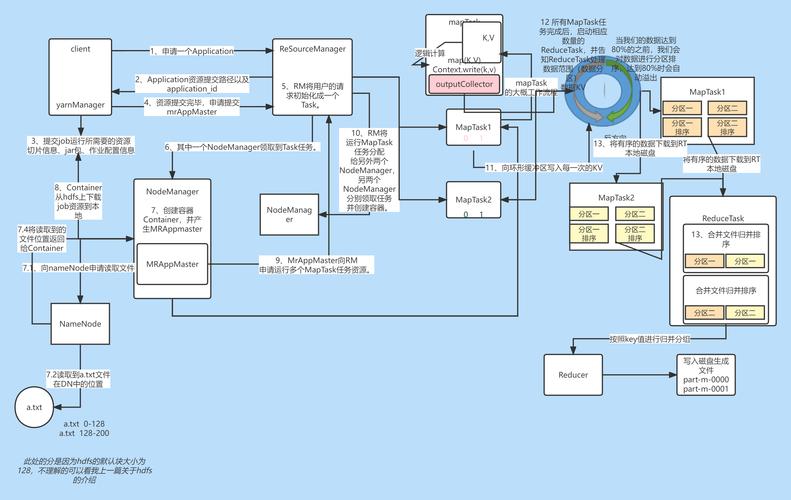
1、输入: 每个Reducer接收到一个键值对列表,其中键是相同的,值是来自不同Mapper的列表。
2、规约函数: 对每个键值对应用规约函数,生成最终的结果。
3、输出: Reducer的输出是最终的处理结果。
合并段
合并段是在Shuffle阶段中进行的,它的目的是将来自不同Mapper的具有相同键的值合并成一个列表,这个过程可以进一步细分为以下几个步骤:
1、分组: 将所有具有相同键的值组合在一起。
2、排序: 对每个组内的值进行排序(如果需要)。
3、合并: 将排序后的值合并成一个列表。
相关问题与解答
问题1: MapReduce中的合并段是如何工作的?
解答: 在MapReduce的Shuffle阶段,合并段负责将来自不同Mapper的具有相同键的值合并成一个列表,所有键值对根据键进行排序,确保具有相同键的值都在一起,这些键值对被分配给不同的Reducer,每个Reducer接收到一个键值对列表,其中键是相同的,值是来自不同Mapper的列表。
问题2: MapReduce中的合并段是否需要对所有值进行排序?
解答: 在MapReduce的合并段中,是否需要对所有值进行排序取决于具体的应用场景和需求,在某些情况下,可能需要对值进行排序以确保特定的顺序或执行某些类型的聚合操作,在其他情况下,可能不需要排序,因为最终的结果只关心键的数量而不是它们的顺序,是否进行排序取决于具体的业务逻辑和数据处理需求。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/589464.html
 微信扫一扫
微信扫一扫