

MapReduce基本原理

MapReduce是一个编程模型,用于处理和生成大数据集,该模型主要包括两个部分:Map(映射)和Reduce(归约),这一模型是面向大规模数据处理的,特别是在分布式环境下。
1.MapReduce 概念
Map:映射操作,用于处理输入数据,生成一组中间键值对。
Reduce:归约操作,用于合并所有具有相同键的值,以产生最终结果。
2.工作原理
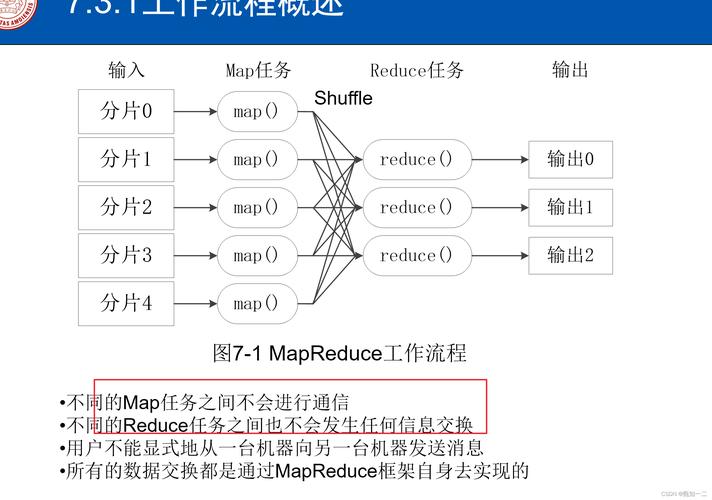
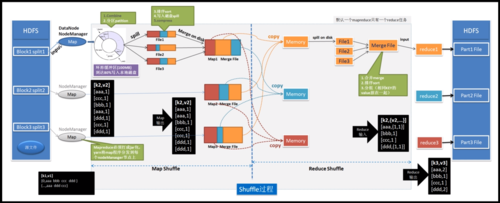
数据分割:输入数据被分割成多个数据块,每个数据块由不同的Map任务处理。
Map阶段:每个Map任务读取数据块并产生键值对。
Shuffle阶段:系统按照键对Map的输出进行排序和分组,准备Reduce阶段。
Reduce阶段:每个Reduce任务处理由Map阶段产生的具有相同键的所有值。
3.MapReduce执行流程
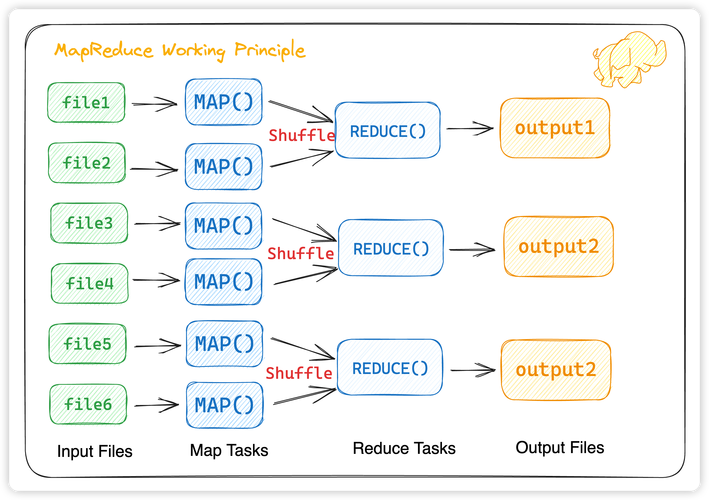
提交作业:用户通过Hadoop客户端提交MapReduce作业。
作业初始化:根据配置,将输入数据分片,并创建Map和Reduce任务。
任务分配:JobTracker根据网络位置等将任务分配给TaskTracker。
执行任务:Map任务执行后,Reduce任务开始执行。
结果输出:Reduce任务完成后,结果存储在HDFS中。
4.MapReduce特点
易于编程:隐藏了并行化、分布式处理、容错等复杂性。
高效处理:在上千节点的大型集群上可靠地处理大规模数据。
容错性:通过重新执行失败的任务来实现高可用性。
5.适用场景与限制
适用场景:日志分析、大数据量的简单运算等。
限制:不适合实时计算和复杂算法处理。
相关组件
| 组件名称 | 功能描述 |
| HDFS | 提供高吞吐量的数据访问,适合存储大规模数据集 |
| Hadoop集群 | 运行MapReduce任务的资源集合 |
相关问题与解答
Q1: MapReduce如何处理数据倾斜问题?
A1: 可以通过Map阶段的combine或者使用更复杂的负载均衡策略来减轻数据倾斜带来的影响。
Q2: MapReduce是否适合实时数据处理?
A2: 不适合,因为MapReduce设计为批处理模型,对于实时数据处理有较大延迟。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/589520.html
 微信扫一扫
微信扫一扫