

MapReduce倒排索引_MapReduce

MapReduce是一种编程模型,用于处理和生成大数据集的并行算法,倒排索引是搜索引擎中常用的数据结构,用于快速查找包含特定单词或短语的文档,小编将详细介绍如何使用MapReduce实现倒排索引。
1. Map阶段
在Map阶段,输入通常是一组文档(例如网页),每个文档被分配给一个Map任务,该任务负责处理单个文档并输出键值对,键是文档中出现的单词,值是包含该单词的文档ID。
def map(document_id, text):
words = text.split()
for word in words:
emit(word, document_id)
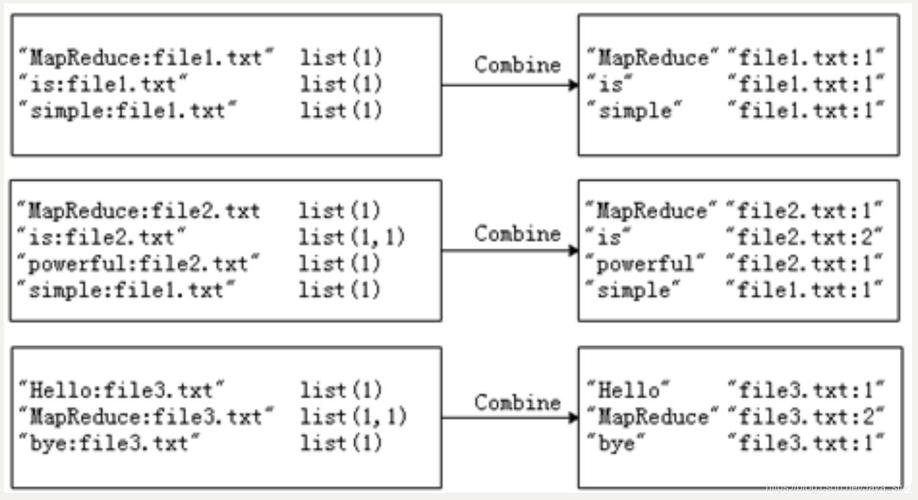
2. Shuffle阶段
Shuffle阶段将所有具有相同键的值组合在一起,并将它们发送到同一个Reduce任务,在这个例子中,所有具有相同单词的文档ID将被组合在一起。
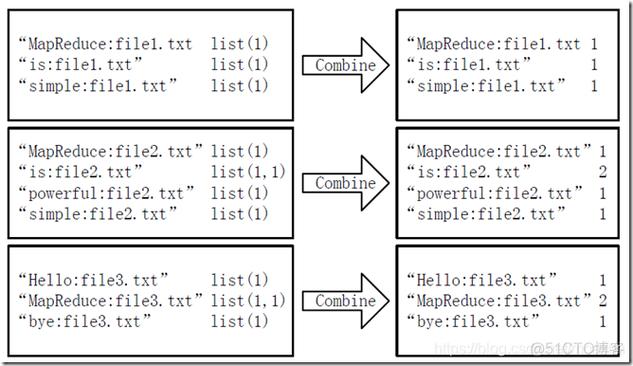
3. Reduce阶段
Reduce阶段接收来自Shuffle阶段的键值对,并对每个键执行聚合操作,在这个例子中,聚合操作是将同一单词的所有文档ID合并成一个列表。
def reduce(word, document_ids):
# Combine all document IDs that contain the word into a list
combined_ids = list(set(document_ids))
emit(word, combined_ids)
4. 结果存储
最终的结果是一个倒排索引,其中每个单词都映射到一个包含该单词的文档ID列表,这个倒排索引可以用于快速检索包含特定单词的文档。
相关问题与解答:
1、问题:MapReduce中的Shuffle阶段是如何工作的?
解答: Shuffle阶段的主要任务是将Map阶段的输出按照键进行排序和分组,它确保所有具有相同键的值都被发送到同一个Reduce任务,这样,Reduce任务就可以针对特定的键进行处理,而不需要处理所有的键值对。
2、问题:为什么在Reduce阶段需要使用集合来合并文档ID?
解答: 使用集合是为了去除重复的文档ID,由于Map阶段可能会为同一个单词产生多个相同的文档ID,因此我们需要确保在Reduce阶段得到的文档ID列表中没有重复项,通过将文档ID转换为集合,我们可以自动去除重复项,然后再转换回列表以供后续使用。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/589743.html
 微信扫一扫
微信扫一扫