

MapReduce的作用

与数据处理原理
MapReduce是一个由Google提出并广泛使用的编程模型,用于处理和生成大数据集,该模型在Hadoop框架中得到了实现,允许大规模数据集通过分布式计算资源进行高速并行处理。
数据处理机制
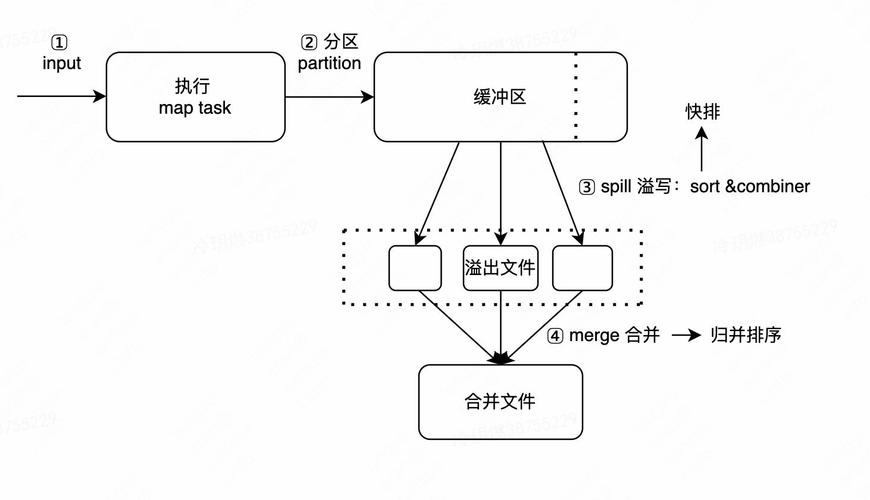
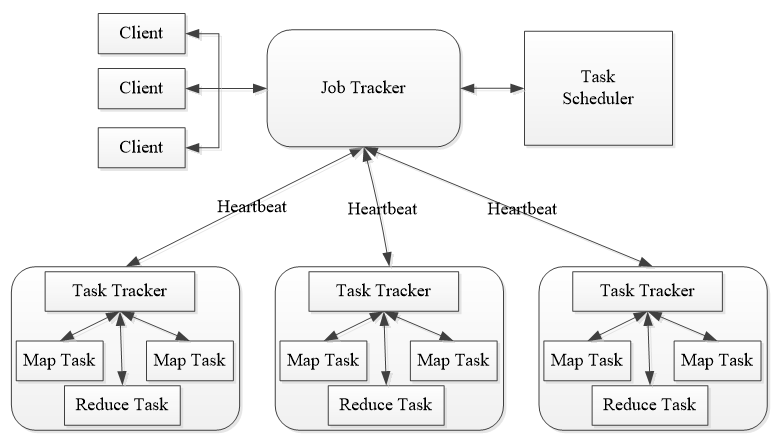
MapReduce的操作可以分为三个基本阶段:Map、Shuffle和Reduce,Map阶段对数据进行过滤和排序;Shuffle阶段负责数据的分组和传送;Reduce阶段则进行汇总或合并操作。
优势与应用
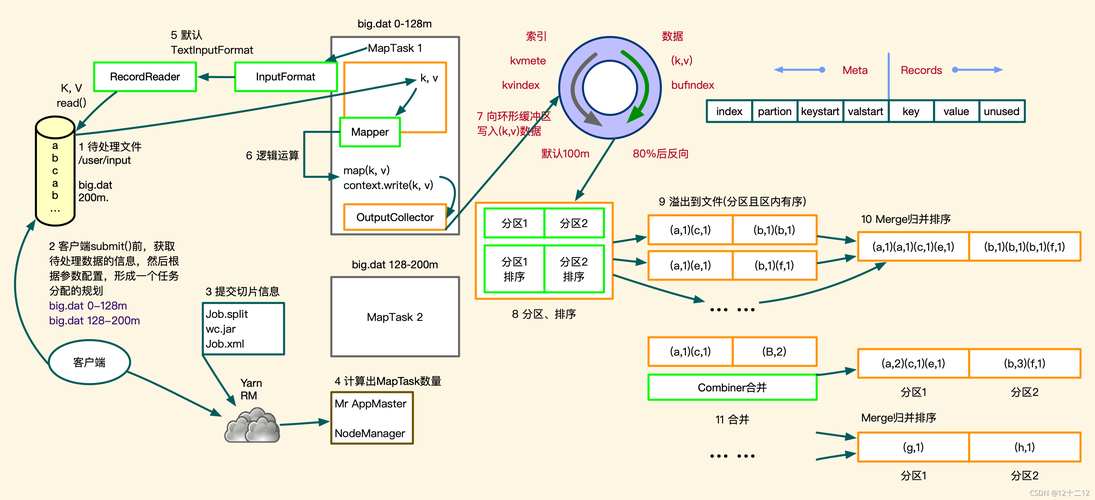
MapReduce的优势在于其简单性和扩展性,使得开发者可以轻松编写出处理海量数据的程序,由于其高效的并行处理能力,MapReduce常被应用于日志分析、数据挖掘等领域。
CSG文件共享的作用
功能与访问方式
CSG(云存储网关)提供标准文件共享协议,如NFS和SMB,允许用户无缝接入公有云对象存储,实现数据的实时共享,这种设置便于企业将数据在本地存储与云端之间迁移和同步,支持热数据缓存以优化访问速度。
应用场景
CSG的应用场景包括数据备份归档、灾难恢复等,它支持部署在云上或本地,满足不同业务需求,通过文件共享,多个用户可以同时访问相同的数据,增强了数据协作的效率。
相关问答
1、MapReduce如何处理数据倾斜问题?
答:数据倾斜通常指在分布式处理中某些节点处理的数据量远大于其他节点,为处理这一问题,可以采用更复杂的Partitioning策略,确保数据均匀分配到各个节点,或者增加Reduce任务的数量来平衡负载。
2、CSG文件共享是否支持多版本控制?
答:是的,CSG文件共享支持多版本控制,这意味着用户可以根据需要恢复到文件的早期版本,这对于数据的错误恢复和历史状态管理非常有用。
3、MapReduce的输出结果如何存储?
答:MapReduce的输出通常存储在Hadoop分布式文件系统(HDFS)中,这是因为HDFS设计用来存储大规模数据,并且能够提供高吞吐量的数据访问,非常适合与MapReduce配合使用。
4、CSG文件共享在数据迁移中扮演什么角色?
答:在数据迁移中,CSG文件共享充当了桥梁的角色,它连接本地存储和云端对象存储,使得数据可以在两者之间高效转移,这在执行数据备份、归档及灾难恢复策略时尤为重要。
5、MapReduce适用于哪些类型的大数据应用?
答:MapReduce特别适用于批量处理大规模数据集的应用,如日志分析、推荐系统、数据挖掘、机器学习模型训练等,这些应用需要处理和分析大量数据,而MapReduce提供了一种有效的方式来并行处理这些数据。
6、CSG文件共享的数据安全性如何保证?
答:CSG文件共享通过多种手段保证数据安全,包括数据加密传输、访问控制列表(ACLs)以及身份验证和授权机制,这些措施帮助确保只有授权用户可以访问敏感数据,且数据传输过程不会被截获或篡改。
本文详细介绍了MapReduce的作用及其数据处理原理,以及CSG文件共享的功能和应用场景,MapReduce通过其独特的Map、Shuffle、Reduce流程高效处理大规模数据集,而CSG文件共享则通过提供标准的文件共享协议简化了数据在本地与云端之间的迁移和同步过程,两者都在现代数据处理和云存储领域发挥着重要作用。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/589759.html
 微信扫一扫
微信扫一扫