

MapReduce与MySQL的整合应用

在大数据时代,数据的处理和分析变得日益重要,MapReduce作为处理大规模数据集的编程模型,常与数据库系统如MySQL结合使用,以实现复杂的数据处理任务,本文将详细介绍如何通过MapReduce读取MySQL的数据,完成数据处理,并将结果存回MySQL的过程。
基本概念
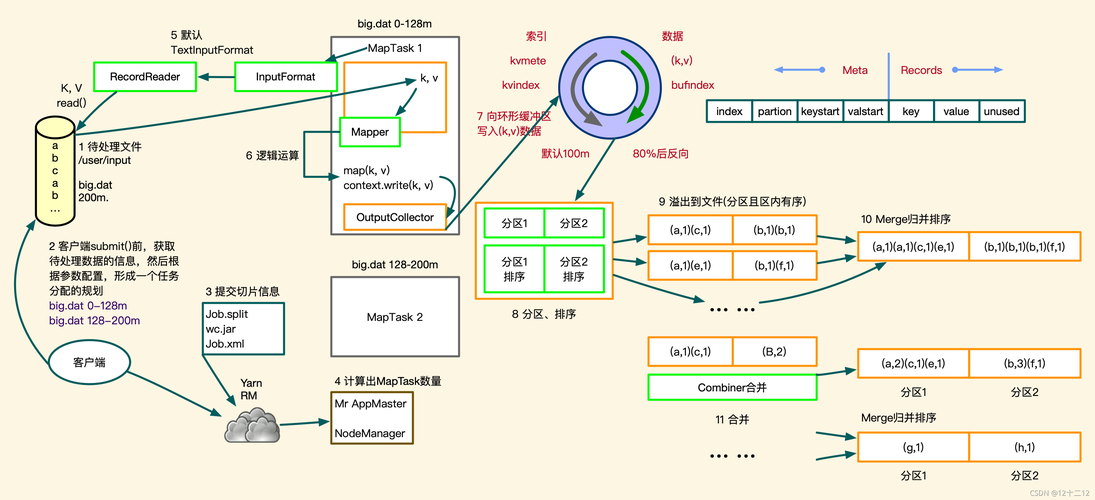
1、MapReduce模型:MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,它包括两个主要阶段:Map阶段和Reduce阶段。
2、MySQL数据库:MySQL是一个广泛应用在全球的开源关系型数据库管理系统,它以其高性能、稳定性和易用性著称。
3、数据交互需求:在实际应用中,经常需要从MySQL导入数据到Hadoop或从MapReduce导出计算结果到MySQL。
操作步骤
配置数据库连接
设置连接参数:首先需要配置Hadoop集群与MySQL数据库的连接信息,包括数据库URL、用户名、密码等。
数据读取与处理
读取MySQL数据:使用MapReduce作业读取存储在MySQL中的原始数据。
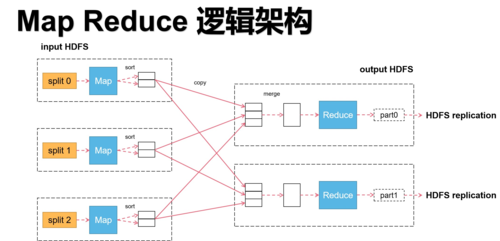
数据处理:在Map阶段对数据进行初步筛选和分类;在Reduce阶段进行汇总或进一步处理。
结果存储
创建表结构:在MySQL中创建一个新表用于存储处理后的结果。
写入数据:将MapReduce作业的结果写回MySQL数据库中相应的表内。
注意事项
数据格式匹配:确保MapReduce作业输出的数据格式与MySQL表中的结构相匹配。
性能优化:考虑在MapReduce作业中加入适当的优化策略,比如合理设置Map和Reduce任务的数量,以提高数据处理效率。
代码示例
数据输入:自定义类接收源数据,使用Text.writeString(dataOutput, words)序列化数据,因为DataOutput接口没有直接处理String类型的方法。
SQL操作:在JDBC操作中,statement.setString(1, words)用于设置SQL命令的参数,数字代表MySQL表中的列序号。
相关问题与解答
Q1: MapReduce处理过程中如何确保数据的准确性?
A1: 确保数据准确性需要在代码逻辑中加入适当的验证和错误处理机制,可以通过单元测试来验证每个步骤的正确性。
Q2: 如何提高MapReduce作业的效率?
A2: 提高MapReduce作业效率可以从多方面入手,例如合理划分Map和Reduce任务,优化数据读取和写入的方式,选择合适的数据序列化方法,以及调整Hadoop集群的配置参数等。
通过MapReduce与MySQL的结合使用,可以有效地处理和分析大规模数据集,满足各种实时查询和OLAP的需求,通过合理的配置和优化,可以进一步提高数据处理的效率和准确性。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/589783.html
 微信扫一扫
微信扫一扫