

关于使用MapReduce进行文本相似度分析的问题,可以通过向量空间模型、余弦相似度计算以及MapReduce框架的应用来详细解析,这些技术共同作用,为处理大规模文本数据提供了有效的解决方案。
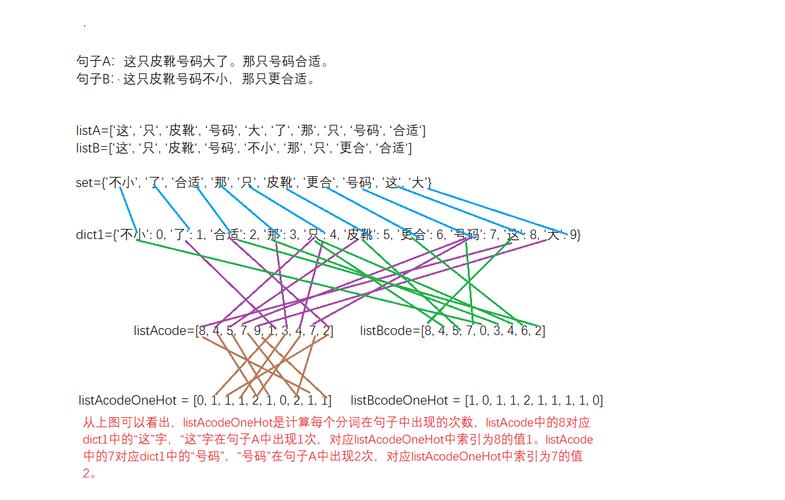

向量空间模型(VSM)
向量空间模型是将文本内容转换成向量的一种常用方法,在该模型中,每份文档都被视为在多维空间中的一个点,其中每个维度代表一个独特的词语,利用词频(TF)或TFIDF算法,可以计算出每个词在文档中的权重,形成文档向量,这种表示方式便于计算机处理和分析文本数据。
余弦相似度计算
余弦相似度是通过计算两个向量之间的夹角的余弦值来度量它们的相似程度,在文本分析中,夹角越小,表明两份文本越相似,这种方法因其计算效率高、能较好地反映文本间的相似关系而被广泛采用。
MapReduce框架应用
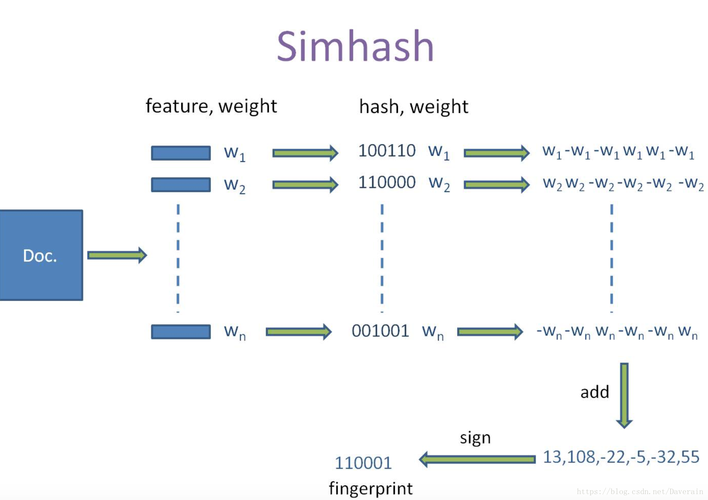
MapReduce是一种编程模型,用于大规模数据集的并行运算,它通过将任务分为映射(Map)和归约(Reduce)两个阶段,可以高效地处理大量数据,在文本相似度分析中,Map阶段可以用于计算单个文本对的相似度,而Reduce阶段则可以汇总所有的相似度结果,从而完成整个数据集的相似度分析。
具体应用
在实际运用中,MapReduce框架能够有效地处理大规模文本集的相似度计算问题,在文本分类、聚类分析等任务中,通过分布式计算,可以大幅提高处理速度,解决传统单机处理模式下内存限制和计算效率低下的问题。
相关问题与解答
如何选择合适的相似度计算方法?
选择相似度计算方法时,需要考虑数据的特性和计算资源,余弦相似度适用于高维稀疏数据,如文本数据,且计算相对简单,但在特定情况下,也可以考虑其他方法如欧氏距离等,根据实际需求和效果来决定最合适的方法。
MapReduce框架在文本相似度计算中的优势是什么?
MapReduce框架的最大优势在于其高效的并行处理能力,对于大规模数据集,它可以显著减少计算时间,同时减轻单机内存压力,使得处理海量文本数据成为可能,它还具有良好的扩展性和容错性,适合在分布式环境中运行。
通过上述详细解析可以看出,结合向量空间模型、余弦相似度及MapReduce框架,为文本相似度分析提供了一种高效、可扩展的解决方案。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/589863.html
 微信扫一扫
微信扫一扫