

MapReduce是一种流行的分布式计算模型,用于处理大规模数据集,它通过将任务分为Map阶段和Reduce阶段,实现了对数据的快速并行处理,小编将详细介绍MapReduce的基本概念、核心组件以及一个简单的应用实例。

MapReduce基本概念
Map阶段:在Map阶段,输入数据被分解成一系列的键值对,这个阶段的主要任务是将数据进行初步的处理和分类。
Reduce阶段:Reduce阶段则负责处理由Map阶段产生的键值对,通常执行一些聚合操作,如统计、求和等,最终生成输出结果。
Hadoop集群:MapReduce任务通常运行在Hadoop集群上,这允许它在多台机器上并行处理数据,从而加快数据处理速度。
HDFS存储:Hadoop Distributed File System(HDFS)是Hadoop的文件系统,它可以提供可靠、快速的数据传输,非常适合存储大规模数据集供MapReduce任务使用。

核心组件
Mapper:Mapper是实现Map阶段功能的代码组件,它接受原始数据作为输入,执行某种转换操作,然后输出一组键值对,这些键值对会作为Reduce阶段的输入。
Reducer:Reducer处理由Mapper输出的键值对,根据键进行分组,并对每个组的值进行聚合操作,以产生最终的输出结果。
MapReduce编程模型
编程模型简化:MapReduce大大简化了分布式编程的复杂性,开发人员即使没有分布式并行编程的经验,也可以容易地将自己的程序运行在分布式系统上。

数据流设计:在MapReduce中,数据流的设计非常关键,开发者需要精心设计Map函数和Reduce函数,以确保数据可以有效地流动和处理。
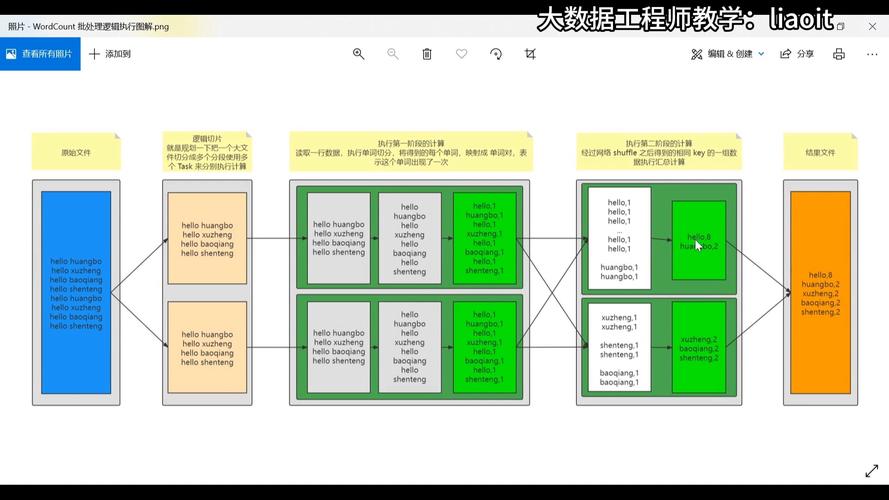
Word Count示例
词频统计:Word Count是MapReduce的一个经典例子,用于统计文本数据中各单词的出现次数,在Map阶段,程序会将文本数据分割成行,然后将每行文本拆分成单词,并为每个单词生成一个键值对,在Reduce阶段,程序会对相同键(即相同的单词)的值进行汇总,得到每个单词的总出现次数。
相关问题与解答
Q1: MapReduce如何处理数据倾斜问题?
A1: 数据倾斜是指MapReduce作业中某些节点处理的数据量远大于其他节点,解决这一问题的策略包括在Map阶段使用更复杂的键设计或在Reduce阶段之前使用额外的排序和分区步骤来平衡负载。
Q2: MapReduce模型在哪些场景下不适用?
A2: MapReduce不适合实时数据处理或交互式查询,因为它是为批量处理设计的,对于需要低延迟响应的应用,如在线事务处理系统,应考虑使用其他模型如Apache Storm或Spark Streaming。
MapReduce通过其独特的编程模型和运行机制,为处理大规模数据集提供了强大的支持,尽管在某些应用场景下存在局限性,如实时数据处理,但通过适当的设计和优化,MapReduce仍然是处理大规模数据的强大工具。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/590050.html
 微信扫一扫
微信扫一扫