

在多CPU内核环境下,针对MapReduce的调优配置是提高数据处理效率的重要环节,小编将详细探讨在多CPU内核下如何进行MapReduce调优配置。

操作系统级别调优
1、文件和网络连接限制调整
增大打开文件数据限制:默认情况下,操作系统对同时打开的文件数量有限制,在大数据环境中,需要处理大量文件,因此需要增加这个上限以支持更多的并发文件操作。
网络连接上限调整:调整net.core.somaxconn参数可以提升TCP接收缓存的大小,允许系统中更多处于TIME_WAIT状态的连接,从而提高网络带宽使用率。
2、关闭swap分区
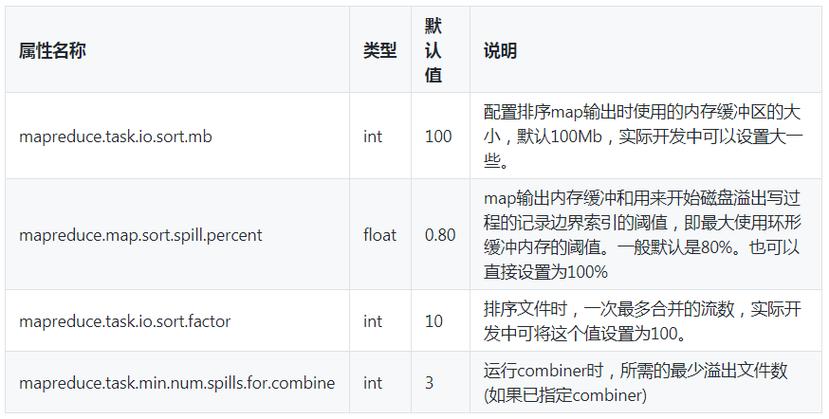
影响性能:当物理内存不足时,系统会使用swap分区,但这会导致磁盘I/O操作增多,进而降低程序执行效率,在Hadoop环境中,应尽量关闭swap分区以避免性能损失。
预读缓存区大小:通过增加预读缓存区的大小,可以减少读取数据时的磁盘寻道次数和I/O等待时间,从而加速数据的读写速度。
3、优化文件描述符上限
epoll模型优化:对于使用epoll I/O复用模型的系统,适当调整文件描述符上限可以提升Hadoop RPC(远程过程调用)的并发能力。
HDFS参数调优
1、核心配置文件调整
hadoop.tmp.dir:此参数指定了Hadoop运行时的临时目录位置,默认通常位于/tmp,但为了更好的性能和管理,建议手动配置该选项,避免与系统的临时文件混在一起。
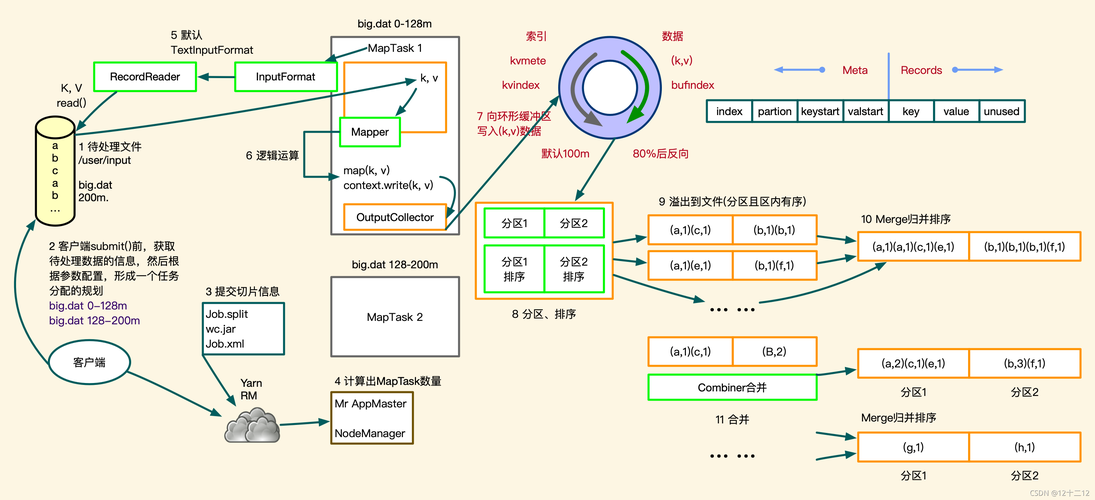
MapReduce参数调优
1、内存分配
调整map和reduce的内存:根据作业的具体需求调整mapreduce.map.memory.mb和mapreduce.reduce.memory.mb,这有助于优化每个任务的内存使用,避免OutOfMemoryError异常。
2、作业调度及并行度优化
优化并行度:合理设置作业的并行度,可以使任务更高效地运行在多核CPU上,考虑数据本地性,减少数据在网络中的传输量。
客户端与服务器端配置
1.配置入口
服务器端配置:进入Yarn服务参数的“全部配置”界面进行参数调整。
客户端配置:直接在客户端修改相应的配置文件,如HDFS客户端配置文件路径...
可以看到在多CPU内核环境下调优MapReduce涉及多个层面和参数,正确的调优策略不仅能充分发挥硬件性能,还能显著提升作业的处理速度和效率,将对两个常见问题进行解答,以进一步巩固上述调优措施的理解和应用。
相关问题与解答
Q1: 为何关闭swap分区能提升性能?
A1: Swap分区被用作虚拟内存的扩展,当物理内存不足以支撑当前运行的程序时,系统会将部分数据暂时移至磁盘上的swap分区,磁盘的读写速度远低于RAM,频繁的swap交换会导致大量磁盘I/O操作,从而显著降低程序执行效率,在内存充足的大数据处理环境中,关闭swap分区可以避免这种性能损失。
Q2: 如何确定MapReduce作业的并行度?
A2: 并行度决定了同时执行的任务数,过高或过低的并行度都可能影响作业性能,理想的并行度取决于多个因素,包括CPU核心数、内存大小以及I/O容量,可以通过逐步增加并行度的方式测试作业的执行效率,找到最优配置,也需考虑数据的本地性和集群中其他作业的资源需求,以实现整体资源的高效利用。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/590094.html
 微信扫一扫
微信扫一扫