

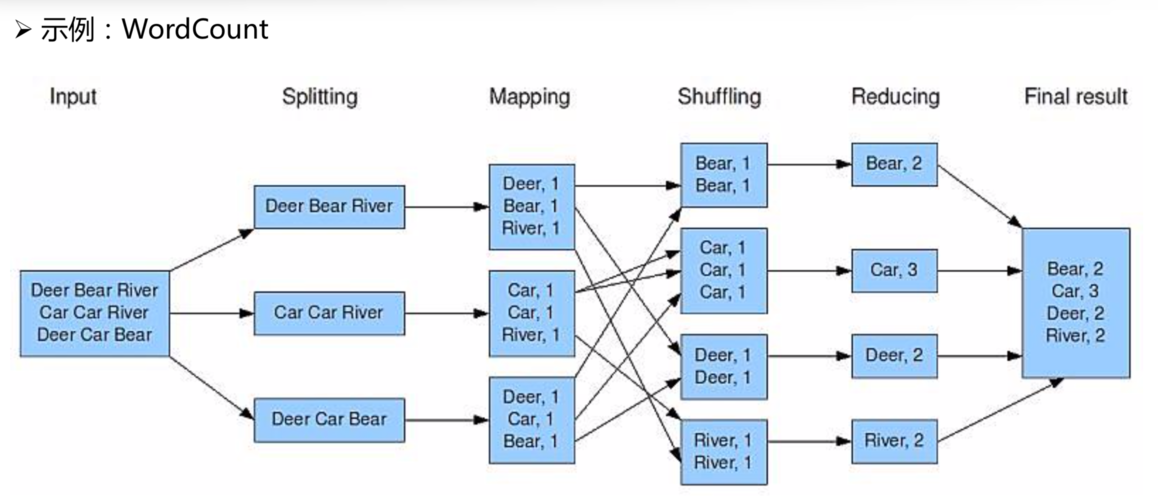
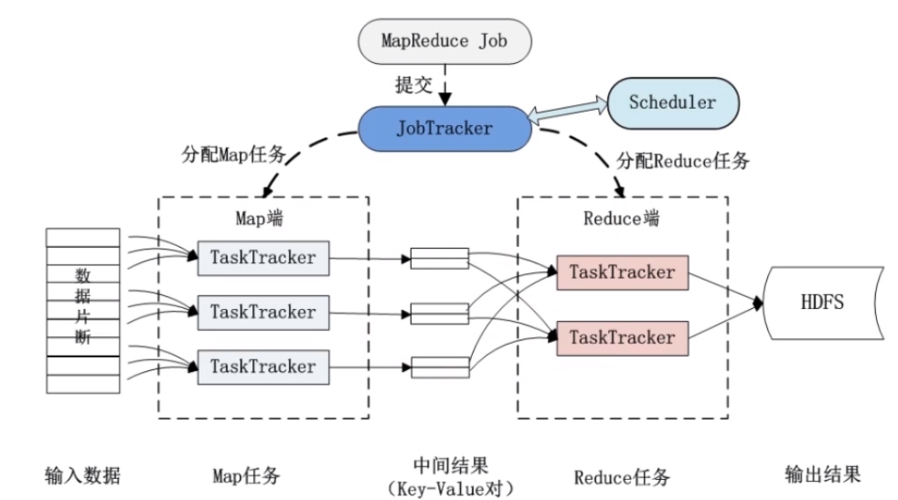
在大数据处理框架Hadoop中,MapReduce编程模型是核心之一,它通过将任务分配到多个节点上并行处理大规模数据集来提高处理速度,Map和Reduce是MapReduce模型中的两个主要阶段,每个阶段的任务数量会直接影响作业的执行效率和资源利用情况,本文将详细介绍如何设置MapReduce作业中的Map和Reduce数量,以及影响这一设置的因素。
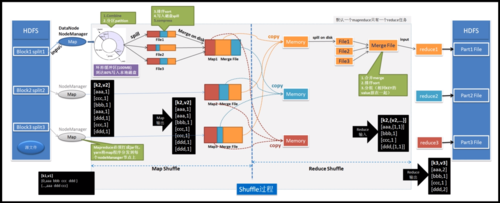

调整Map数量
1、配置参数
Hive语句设置:在Hive中,可以通过SET mapreduce.job.maps=<number>;来设定Map的数量。
Hadoop参数:对于Hadoop, 可以通过mapred.map.tasks参数进行设置,但这是一个仅作为参考的数值。
2、影响因素
数据块大小(Split):Map的数量受输入数据块大小的影响,可以通过调整mapreduce.input.fileinputformat.split.maxsize等参数来改变。
集群资源:实际可用的集群资源也会影响可创建的Map数量,需根据具体资源调整Map数量以优化性能。
调整Reduce数量
1、配置参数
Hive语句设置:类似于Map设置,Reduce的数量可以通过SET mapreduce.job.reduces=<number>;在Hive中进行配置。
2、影响因素
分区(Partition):Reduce的数量受到输出数据分区方式的影响,每个分区会对应一个Reduce任务。
控制Map与Reduce数量的原则
1、数据量匹配
大数据量:对于大数据量,应增加Map数量以充分利用集群的处理能力。
单个Map任务的数据量:确保每个Map任务处理合适的数据量,避免任务过重或过轻。
2、资源与性能平衡
资源利用率:合理设置Map和Reduce的数量可以最大化资源利用率,避免资源浪费。
性能优化:适当的任务数量可以加速数据处理过程,改善整体性能表现。
问题与解答
Q1: 如何确定最佳的Map数量?
A1: 最佳的Map数量取决于多个因素,包括输入数据的大小、格式、存储方式以及集群的资源情况,一种常用的方法是根据输入数据的总大小除以单个Map任务理想处理的数据量来计算,考虑到网络和磁盘I/O的限制,通常建议每个Map任务处理10100MB数据。
Q2: 是否应该同时增加Map和Reduce的数量?
A2: 这取决于具体的作业需求和系统资源,如果系统资源允许,且数据处理过程中Map和Reduce阶段都是瓶颈,那么同时增加两者的数量可能是有益的,过多地增加任何一个阶段的任务数可能导致资源争用和管理系统开销增大,反而降低效率,应根据作业的具体情况进行逐步调整并测试最佳效果。
正确设置和管理MapReduce作业中的Map和Reduce数量是优化数据处理性能的关键步骤之一,通过理解其背后的机制和原则,用户可以更有效地利用Hadoop集群资源,加速数据处理过程,提高整体的工作效率。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/590150.html
 微信扫一扫
微信扫一扫