

MapReduce 在 Python 中的应用
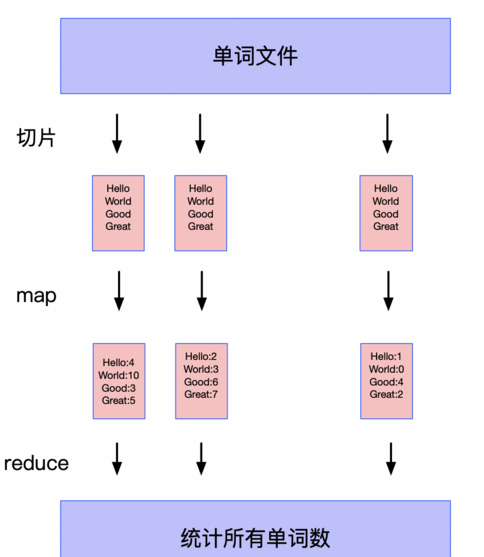

MapReduce是一种编程模型,用于处理和生成大数据集,它由两个步骤组成:Map(映射)步骤和Reduce(归约)步骤,Python中可以使用Hadoop Streaming或其他库来实现MapReduce。
1. MapReduce 简介
1.1 Map阶段
Map阶段的任务是将输入数据分割成多个独立的块,并对每个块进行处理,每个块的处理结果是一个键值对的集合。
1.2 Reduce阶段
Reduce阶段的任务是将所有Map阶段的输出按键进行排序,然后对具有相同键的所有值进行归约操作,以生成最终的结果。
2. Python中的MapReduce实现
2.1 使用Hadoop Streaming
Hadoop Streaming允许用户通过标准输入/输出流与Hadoop集群交互,以下是一个简单的例子,演示如何使用Python编写MapReduce程序。
Mapper (mapper.py)
import sys
for line in sys.stdin:
words = line.strip().split()
for word in words:
print(f"{word}\t1")
Reducer (reducer.py)
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
word, count = line.strip().split('\t', 1)
count = int(count)
if current_word == word:
current_count += count
else:
if current_word:
print(f"{current_word}\t{current_count}")
current_word = word
current_count = count
if current_word == word:
print(f"{current_word}\t{current_count}")
运行MapReduce任务
hadoop jar /path/to/hadoopstreaming.jar \n input /path/to/inputfile \n output /path/to/outputdir \n mapper mapper.py \n reducer reducer.py \n file mapper.py \n file reducer.py
2.2 使用mrjob库
mrjob是一个Python库,提供了一种更简洁的方式来编写和运行MapReduce任务,以下是使用mrjob编写的简单示例。
Word Count with mrjob (wordcount.py)
from mrjob.job import MRJob
from mrjob.step import MRStep
class MRWordCount(MRJob):
def steps(self):
return [
MRStep(mapper=self.mapper, reducer=self.reducer)
]
def mapper(self, _, line):
words = line.strip().split()
for word in words:
yield (word, 1)
def reducer(self, word, counts):
yield (word, sum(counts))
if __name__ == '__main__':
MRWordCount.run()
运行MapReduce任务
python wordcount.py inputfile.txt > outputfile.txt
3. 相关问题与解答
问题1: MapReduce的优势是什么?
答案1: MapReduce的主要优势在于其能够处理大规模数据集,它将计算任务分解为多个独立的子任务,这些子任务可以在分布式系统中并行执行,MapReduce还提供了容错性,因为如果某个节点失败,它的任务可以被重新分配给其他节点。
问题2: MapReduce的缺点有哪些?
答案2: MapReduce的一些缺点包括:
对于需要频繁读写磁盘的操作,性能可能不佳,因为MapReduce主要设计用于处理大量数据的批处理任务。
MapReduce不适用于实时数据处理或需要低延迟响应的应用。
对于某些类型的复杂查询或算法,MapReduce可能不是最佳选择,因为它的设计初衷是为了简化复杂的数据处理任务。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/590210.html
 微信扫一扫
微信扫一扫