

MapReduce 源码分析

MapReduce 是一种编程模型,用于处理和生成大数据集,它将任务分成两个阶段:Map 阶段和 Reduce 阶段,本文将深入探讨 Hadoop MapReduce 的源码实现。
1. MapReduce 架构
Hadoop MapReduce 主要包含以下四个组件:
JobTracker:负责资源管理和作业调度。
TaskTracker:执行任务并定期向 JobTracker 报告进度。
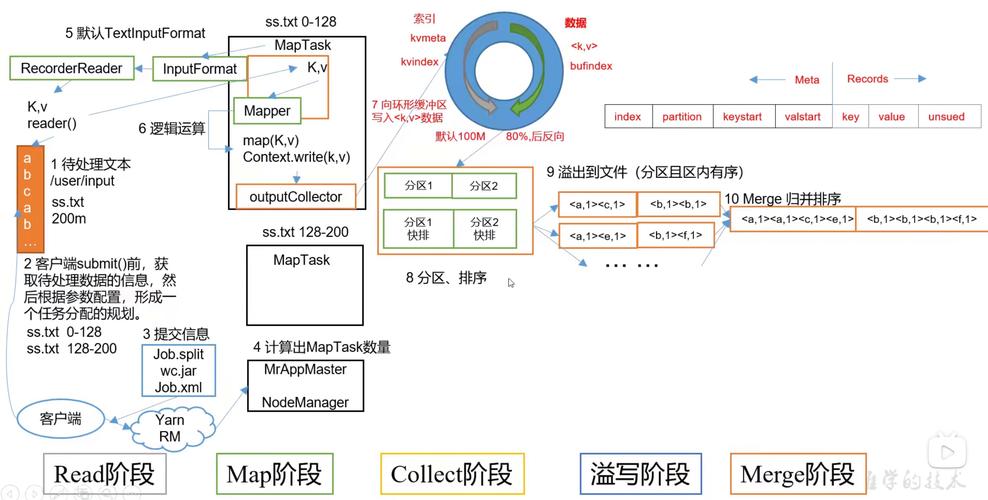
MapTask:执行 Map 阶段的计算。
ReduceTask:执行 Reduce 阶段的计算。
2. Map 阶段
Map 阶段的主要工作是将输入数据切分成多个数据块,并为每个数据块创建一个 Map 任务,Map 任务通过用户编写的 map() 函数处理数据,并输出中间结果(键值对)。
public void map(KEYIN key, VALUEIN value, Context context) throws IOException, InterruptedException {
// 用户自定义逻辑
}
3. Shuffle 和 Sort 阶段
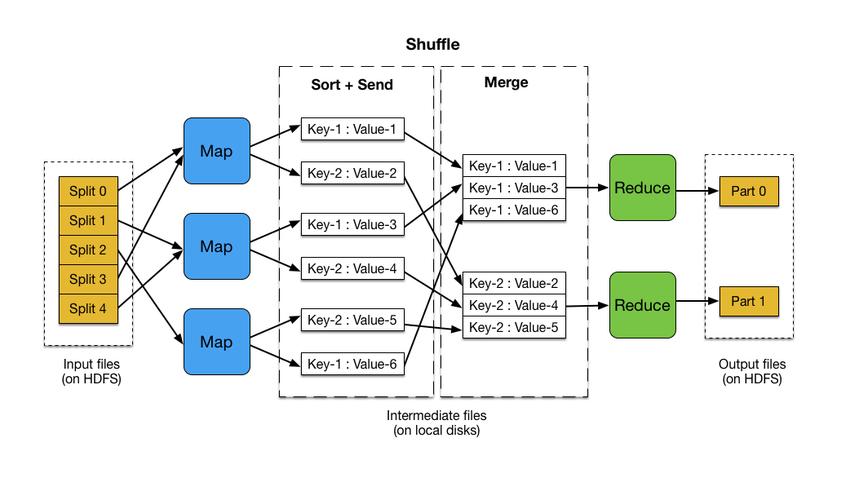
Shuffle 和 Sort 阶段是连接 Map 和 Reduce 阶段的桥梁,在这个阶段,Map 任务的输出被排序、分组并传输给对应的 Reduce 任务。
// Partitioner 类用于决定键值对发送到哪个 Reducer
public class MyPartitioner extends Partitioner<KEYOUT, VALUEOUT> {
public int getPartition(KEYOUT key, VALUEOUT value, int numReduceTasks) {
// 自定义分区逻辑
}
}
4. Reduce 阶段
Reduce 阶段接收来自 Map 任务的已排序和分组的数据,并通过用户编写的 reduce() 函数进行处理,最终输出结果。
public void reduce(KEYIN key, Iterable<VALUEIN> values, Context context) throws IOException, InterruptedException {
// 用户自定义逻辑
}
5. 相关问题与解答
Q1: MapReduce 如何处理失败的任务?
A1: MapReduce 通过重新执行失败的任务来处理失败情况,JobTracker 会监控所有任务的进度,如果发现某个任务失败了,它会在其他节点上重新调度该任务,MapReduce 确保即使任务失败,也不会影响其他任务的正常执行。
Q2: MapReduce 如何保证数据的一致性?
A2: MapReduce 通过使用输入数据的校验和来确保数据的一致性,在 Map 任务开始之前,框架会计算输入数据的校验和并与存储在文件系统中的校验和进行比较,如果校验和不匹配,则认为数据损坏,任务将不会执行,在数据传输过程中,也会使用校验和来确保数据的完整性。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/590350.html
 微信扫一扫
微信扫一扫 