

使用Scan读取HBase数据的MapReduce实践

基础入门
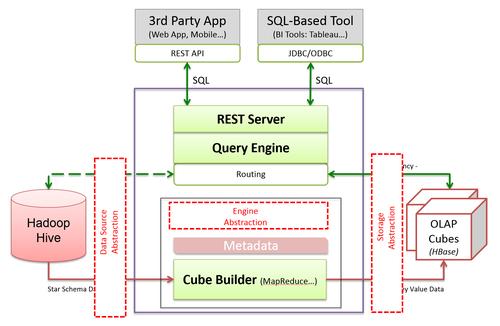
1. HBase与MapReduce的结合
数据导入:利用MapReduce将本地文件系统的数据加载到HBase表中,实现大规模数据的高效迁移。
数据分析:从HBase读取原始数据后,通过MapReduce进行复杂的数据分析任务,如聚合计算、数据挖掘等。
2. Scan类的作用
实例化Table对象:需要先获取HBase表对应的Table实例,才能进一步操作数据。
设置Scan参数:创建Scan对象,并按需设置查询条件,比如StartRow和StopRow,以优化数据读取效率。
3. Scan的工作原理
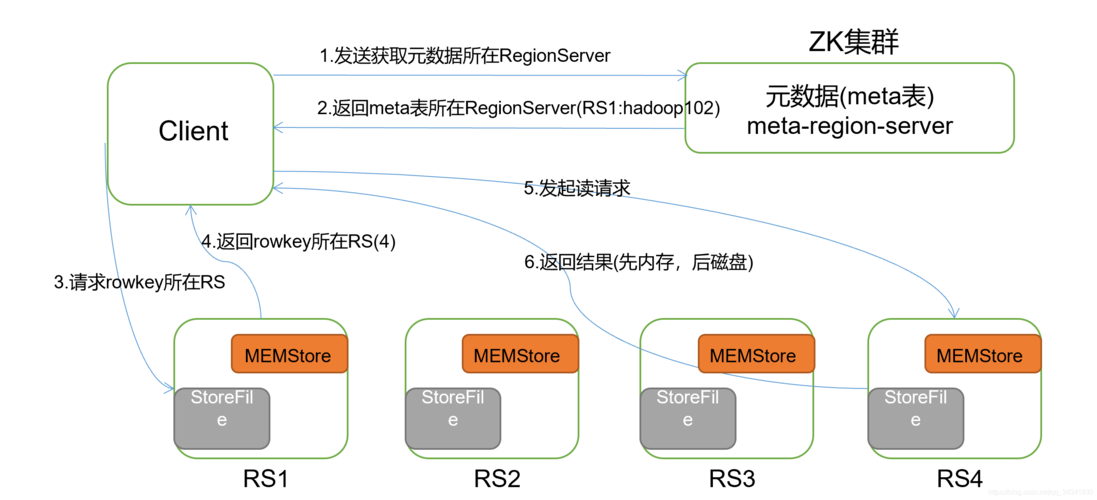
客户端缓存机制:Scan操作并非一次性返回所有结果,而是通过客户端缓存逐步请求数据。
next请求流程:详细描述了从客户端发起next请求到服务器端(RegionServer)响应的过程,以及数据返回的限制。
实操指南
1. 获取Scanner实例
调用getScanner方法:通过Table对象的getScanner()方法获取Scanner实例,以便进行数据迭代。
资源管理:强调使用完毕后应立即关闭Scanner实例,避免消耗过多服务器资源。
2. 配置Scan参数
设置缓存大小:介绍如何配置扫描程序缓存,即在将结果返回给客户端之前可以缓存的行数。
版本兼容性:指出了不同版本HBase间的差异,及如何在各版本中正确设置扫描程序缓存。
常见问题解答
1. 如何处理大量的HBase数据?
使用MapReduce可以有效处理大量数据,通过并行计算框架提高数据处理速度和效率。
2. 如何优化Scan的性能?
优化措施包括设置合理的StartRow和StopRow,以及调整扫描程序缓存的大小,减少网络传输和提高响应速度。
注意事项与最佳实践
1. 确保资源及时释放
使用try/finally块确保ResultScanner使用完毕后能够及时关闭,防止内存泄漏。
监控JVM堆空间的使用情况,避免因扫描器占用过多资源而导致的性能问题。
2. 考虑数据访问模式
根据数据访问频率和查询复杂度选择合适的数据模型和索引策略,以提升Scan的效率。
分析业务需求,可能需要权衡扫描范围与查询性能之间的关系,找到最佳平衡点。
本文档旨在提供使用Scan读取HBase数据时的操作指导和最佳实践,读者需结合自身的业务场景和HBase系统的配置来具体应用这些知识,对于更高级的需求,建议深入理解HBase的内部机制和API文档,以获得更优的性能和功能实现。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/590628.html
 微信扫一扫
微信扫一扫