

MapReduce自定义排序_自定义排序器


MapReduce是一种编程模型,用于处理和生成大数据集,在MapReduce中,排序是一个常见的需求,特别是在处理大量数据时,默认情况下,MapReduce框架使用键值对的键进行排序,有时我们可能需要根据特定的规则或字段进行自定义排序,为了实现这一目标,我们可以使用自定义排序器(Custom Sorter)。
自定义排序器的概念
自定义排序器允许我们在MapReduce作业中定义自己的排序逻辑,它通常由一个实现了WritableComparator接口的类来实现,这个接口需要实现两个方法:compare(WritableComparable w1, WritableComparable w2)和getPartition(WritableComparable w, int numPartitions),前者用于比较两个对象,后者用于确定对象应该分配到哪个分区。
自定义排序器的实现步骤
1、创建自定义排序器类:我们需要创建一个实现了WritableComparator接口的类,假设我们要根据字符串的长度进行排序:
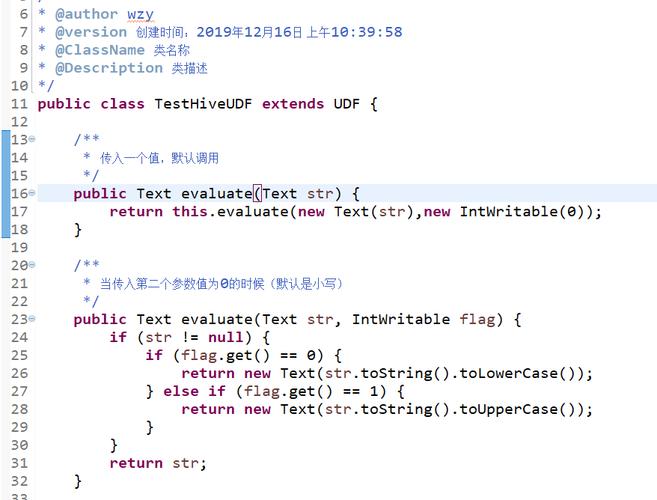
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparator;
public class LengthComparator extends WritableComparator {
public LengthComparator() {
super(Text.class, true);
}
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
Text key1 = (Text) w1;
Text key2 = (Text) w2;
return Integer.compare(key1.toString().length(), key2.toString().length());
}
}
2、配置MapReduce作业:我们需要在MapReduce作业的配置中指定自定义排序器,这可以通过设置job.setSortComparatorClass()方法来完成:
Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "custom sorting example"); // ... other job configurations ... job.setSortComparatorClass(LengthComparator.class);
3、运行MapReduce作业:像往常一样运行MapReduce作业即可,由于我们已经设置了自定义排序器,所以输出结果将按照字符串长度进行排序。
单元表格:自定义排序器的关键要素
| 要素 | 描述 |
| 自定义排序器类 | 继承自WritableComparator并实现其方法 |
compare方法 |
比较两个对象的排序顺序 |
getPartition方法 |
可选,决定对象应分配到哪个分区 |
| 配置MapReduce作业 | 通过job.setSortComparatorClass()设置自定义排序器类 |
相关问题与解答
问题1: 如何修改自定义排序器以按降序排列?

答案: 要按降序排列,只需在compare方法中反转比较的结果即可。
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
Text key1 = (Text) w1;
Text key2 = (Text) w2;
return Integer.compare(key1.toString().length(), key2.toString().length());
}
问题2: 如何在自定义排序器中使用多个字段进行排序?
答案: 可以在compare方法中添加额外的逻辑来比较多个字段,首先比较第一个字段,如果它们相等,则继续比较第二个字段,依此类推。
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
Text key1 = (Text) w1;
Text key2 = (Text) w2;
int lengthComparison = Integer.compare(key1.toString().length(), key2.toString().length());
if (lengthComparison != 0) {
return lengthComparison;
} else {
return key1.toString().compareTo(key2.toString()); // Compare based on the full string if lengths are equal
}
}
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/590632.html
 微信扫一扫
微信扫一扫