


(图片来源网络,侵删)
简介
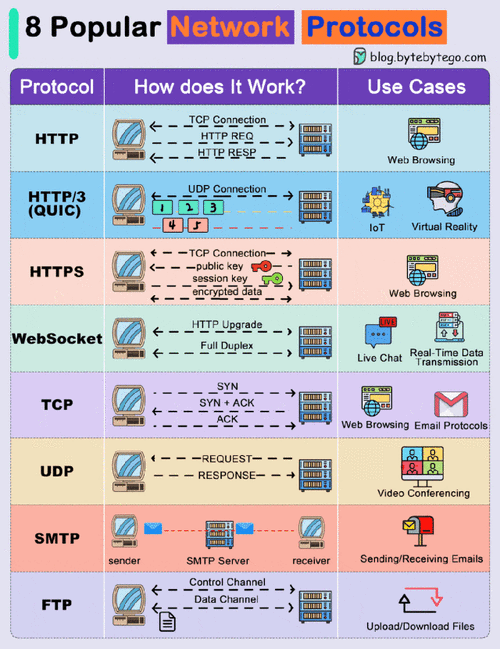
一句话识别(websocket版)是一个基于WebSocket协议的语音识别API服务,它允许用户通过WebSocket连接发送语音数据,并实时接收识别结果,该服务适用于需要快速、连续语音识别的场景,如语音助手、实时字幕等。
功能特点
实时性:通过WebSocket连接,实现低延迟的实时语音识别。
高效性:优化了数据传输和处理过程,提高了识别效率。
(图片来源网络,侵删)
易用性:提供了简单易用的API接口,方便开发者快速集成和使用。
使用流程
1、建立WebSocket连接:通过指定的WebSocket地址建立连接。
2、发送语音数据:将语音数据以二进制格式发送到服务器。
3、接收识别结果:服务器会实时返回识别结果,包括文本内容和置信度等信息。

(图片来源网络,侵删)
4、关闭连接:在完成识别后,关闭WebSocket连接。
代码示例
以下是一个简单的Python代码示例,展示了如何使用一句话识别(websocket版) API:
import websocket
import base64
import json
建立WebSocket连接
ws = websocket.create_connection("wss://example.com/recognize")
发送语音数据
with open("audio.wav", "rb") as f:
audio_data = f.read()
encoded_data = base64.b64encode(audio_data).decode("utf8")
ws.send(json.dumps({"audio": encoded_data}))
接收识别结果
result = ws.recv()
print(result)
关闭连接
ws.close()
相关问题与解答
问题1:如何提高一句话识别的准确性?
答:可以通过以下方法提高识别准确性:
确保音频质量良好,避免噪声干扰。
使用清晰的发音和适当的语速进行录音。
根据应用场景选择合适的语言模型和声学模型。
问题2:一句话识别(websocket版)是否支持多语言识别?
答:是的,一句话识别(websocket版)支持多种语言的识别,具体支持的语言列表可以参考官方文档或联系服务提供商获取。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/590652.html
 微信扫一扫
微信扫一扫 




