

MapReduce参数调优详细解析

调优MapReduce的关键参数和策略
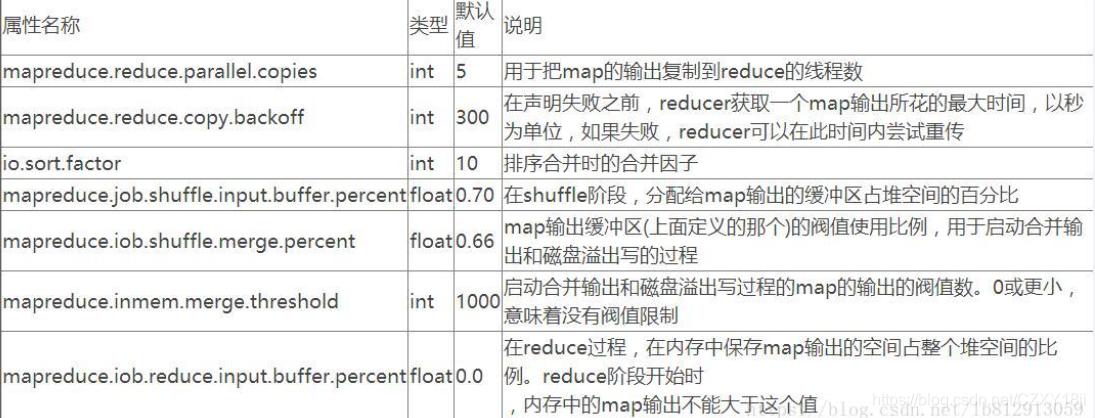
1、资源相关参数调整
内存配置:优化map和reduce任务的内存分配,通过调整mapreduce.map.memory.mb和mapreduce.reduce.memory.mb来控制任务使用的内存量。
执行器数量:配置作业的并发执行器数量,通过yarn.nodemanager.resource.memorymb和yarn.nodemanager.resource.cpuvcores影响整个系统的性能和资源使用率。
2、容错相关参数调整
失败处理:设置任务失败后的重试次数mapreduce.map.maxattempts和mapreduce.reduce.maxattempts,以增强系统的容错性。
数据备份:调整dfs.replication参数来设定HDFS中数据的备份数量,保障数据的安全性与可靠性。
3、MapReduce流程中的参数优化
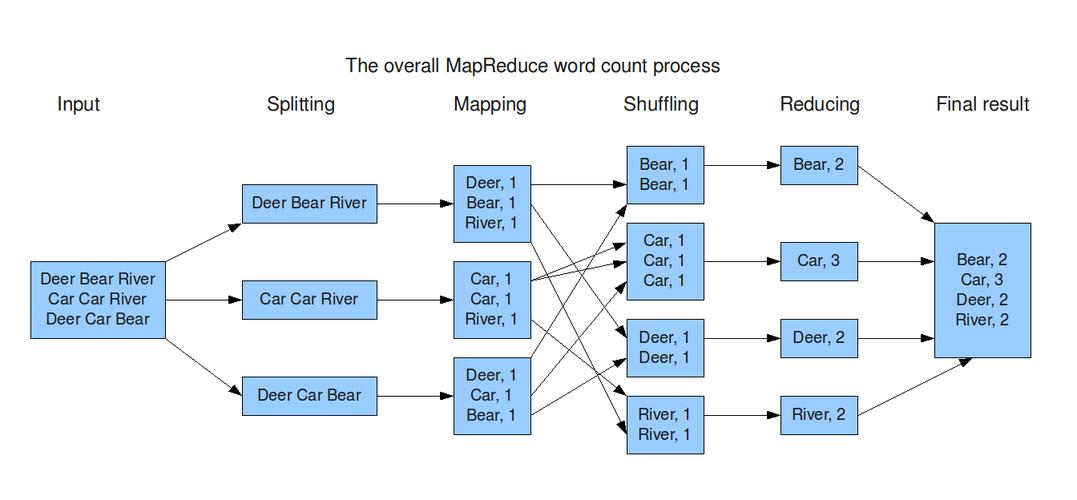
输入阶段:选择合适的InputFormat,如使用CombineTextInputFormat处理小文件问题,减少Map任务的数量和启动时间。
Map阶段:通过调节io.sort.mb和sort.spill.percent参数值,增大触发溢出的内存上限,从而减少磁盘IO操作。
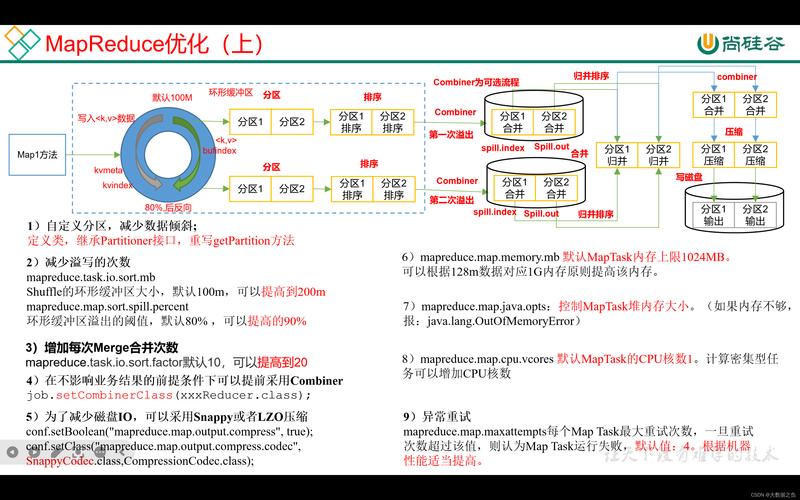
Shuffle和Sort阶段:优化Shuffle性能,配置关键参数mapreduce.job.reduces和mapreduce.shuffle.memory.limit来提升数据处理效率。
Reduce阶段:调整mapreduce.reduce.memory.mb来设定Reduce任务的内存大小,改善大数据集的处理能力。
输出阶段:选择适当的OutputFormat,确保输出数据的正确性和效率。
4、非Hadoop方面的调优
硬件优化:升级硬件设备或优化网络设施,以支持更高效的数据传输和处理。
操作系统配置:调整操作系统参数,如IO调度器、启用预读取机制、关闭Swap等,以提高系统层面的性能。
Java虚拟机(JVM)设置:优化JVM的垃圾回收机制和其他性能相关的参数,如Xmx和Xms。
相关问题与解答
Q1: 如何应对MapReduce作业中的小文件问题?
A1: 可以通过以下几种方法解决小文件问题:
数据合并:在处理前将多个小文件合并成一个大文件。
使用CombineTextInputFormat:这个输入格式可以处理小文件,减少产生的Map任务数。
启用Uber模式:允许单个Map任务处理多个文件,减少任务启动的开销。
Q2: 如何优化MapReduce作业中的内存使用?
A2: 优化内存使用可通过以下方式实现:
调整内存参数:根据作业需求调整Map和Reduce任务的内存配置,如mapreduce.map.memory.mb和mapreduce.reduce.memory.mb。
优化Shuffle性能:通过设置mapreduce.shuffle.memory.limit控制Shuffle过程中的内存使用,避免内存溢出。
JVM调优:适当调整JVM的堆大小及其他性能相关参数,如调整Xmx和Xms来影响垃圾回收和内存分配策略。
深入探讨了MapReduce参数调优的关键方面,包括资源分配、容错机制、流程优化及系统层面的调优,正确的参数设置可以显著提升MapReduce作业的性能和效率,希望这些信息能帮助您更好地理解和应用MapReduce参数调优技术。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/590852.html
 微信扫一扫
微信扫一扫