

MapReduce 优点及与SQL调优对比
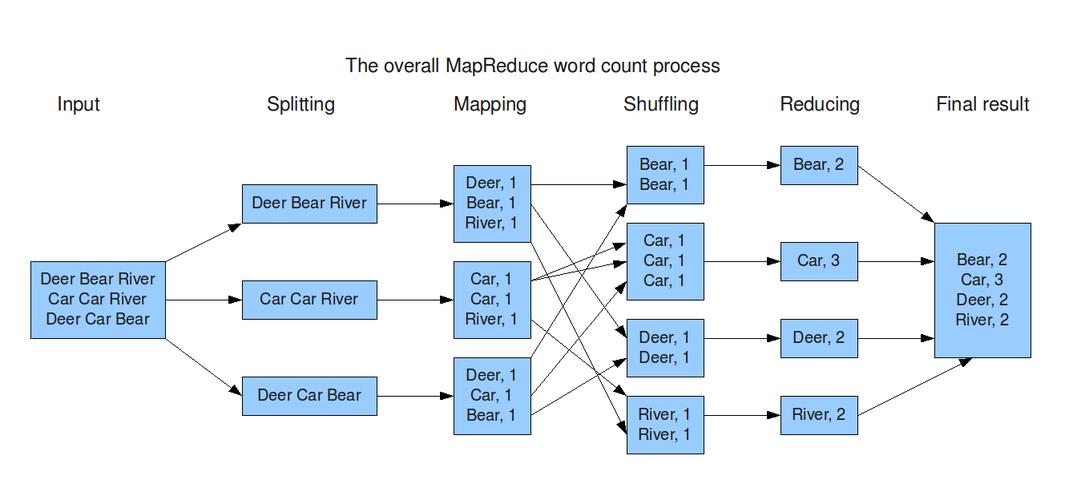
MapReduce的优点
1、可扩展性
大规模数据处理:MapReduce能够在多台机器上处理大规模数据集,适用于PB级别以上数据的离线处理,通过增加计算节点轻松扩展计算能力。
2、灵活性
数据类型灵活:支持结构化和非结构化数据的处理,适用于多种业务场景的数据需求。

3、容错性
自动故障转移:在硬件故障发生时,能自动将任务转移到其他节点执行,无需人工干预,保障计算任务的稳定运行。
4、易于编程
编程模型简洁:MapReduce模型简化了分布式程序编写的复杂度,开发者只需实现Map和Reduce函数即可。
SQL调优的优点与MapReduce比较

1、实时性
查询响应快:SQL数据库通常用于实时查询,响应速度快,适合交互式数据处理和商业智能应用。
2、优化机制
执行计划优化:SQL数据库通过优化器生成高效的执行计划,减少不必要的计算和I/O操作。
3、索引优化
快速数据访问:通过建立索引,SQL数据库能够加速数据检索速度,特别是在OLTP(联机事务处理)系统中表现突出。
4、事务管理
数据一致性保障:SQL数据库支持事务处理,保证数据的一致性和完整性,对于需要强一致性的业务场景至关重要。
相关问题与解答
Q1: MapReduce如何处理数据倾斜问题?
A1: 数据倾斜是指分区中某些Key的数据量远大于其他Key,导致处理时间延长,解决方法包括预先对数据进行采样分析,合理设置Key的分区策略,或者使用MapReduce的 SkewedJoin优化来处理。
Q2: SQL调优中遇到慢查询应如何处理?
A2: 通过执行计划分析慢查询的原因,可能是缺少索引、索引不合理或查询语句编写不当等,根据原因添加或优化索引,重写查询语句,或考虑数据库分区和分表等方法提高查询效率。
MapReduce的可扩展性、灵活性、容错性和易于编程的特点使其成为处理大规模数据集的理想选择,尤其适用于离线批量处理场景,而SQL调优通过索引优化、执行计划调整等手段,提供快速的查询响应和数据一致性保障,更适合实时数据处理和事务性要求高的应用。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/590916.html
 微信扫一扫
微信扫一扫 