

在大数据时代,MapReduce框架作为处理大规模数据集的重要工具之一,其在中文分词和词频统计方面的应用也显得尤为重要,通过将文本数据切分成有意义的单元并统计各单元的出现频率,这一过程对于文本分析、情感分析等领域具有基础性的意义,小编将深入了解MapReduce在中文分词和词频统计中的具体应用及其实践过程:

1、MapReduce框架简介
核心思想:MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,其核心在于“映射(Map)”和“归约(Reduce)”两个阶段。
工作原理:在映射阶段,数据集被分为多个数据块,每个数据块由一个Map任务处理,生成中间的键值对;在归约阶段,所有中间键值对按照键进行聚合,并由Reduce任务处理,产生最终结果。
2、中文分词的重要性
分词定义:中文分词是将连续的中文文本切分成一个个有意义词语的过程,由于中文书写时不像英文有明显的空格分隔,所以分词成为中文文本处理的基础步骤。
应用场景:中文分词不仅应用于文本分析、情感分析,还广泛应用于搜索引擎、语音识别等领域,是中文自然语言处理的一项基础技术。
3、MapReduce在中文分词中的应用
结合工具:在MapReduce框架下进行中文分词,常用的工具有jieba、hanLP等,jieba是一个流行的Python中文分词库,适用于单机模式,而hanLP则更加适合在Hadoop集群上通过MapReduce程序进行分词。
实现方式:在Mapper阶段,可以进行文本的读取和分词处理,输出(word, 1)对;在Reducer阶段,则对相同键的值进行叠加,得出每个词的总频次。
4、MapReduce进行词频统计的流程
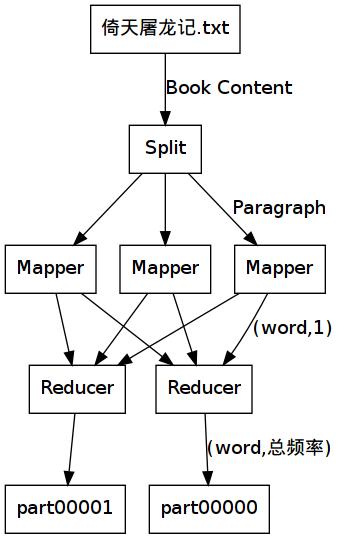
数据分割:输入的中文文本数据集首先被分割成多个数据块,每个数据块由一个Mapper任务进行处理。
Mapper阶段操作:每个Mapper任务对其分配的数据块进行中文分词,并将分词结果转化为(word, 1)形式的键值对输出。
Shuffle和Sort阶段:MapReduce框架自动将Mapper输出的键值对按照键进行排序和分组。
Reducer阶段操作:每个Reducer任务接收到相同键的所有值,对这些值进行汇总计算得到每个词的总频次,并输出最终结果。
5、MapReduce中文分词的实际案例
案例一:在Hadoop平台上利用Streaming模式运行Python MapReduce程序,结合jieba中文分词工具,对小说《天龙八部》进行词频分析。
案例二:通过Hadoop Streaming使用Python脚本进行WordCount,并结合中文分词实现TopN词频统计。
深入探讨了MapReduce在中文分词与词频统计领域的应用,可以发现,无论是通过jieba还是hanLP等工具,MapReduce都能有效地处理大规模的中文文本数据,为进一步的数据分析提供支持,尽管实践中可能会遇到编码或配置方面的问题,但通过仔细的调试和正确的参数设置,这些问题是可以被解决的。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/590920.html
 微信扫一扫
微信扫一扫