

在大数据面试中,MapReduce是一个经常出现的主题,作为一个革命性的大规模数据处理模型,它对处理大量数据的能力至关重要,小编将详细解析一些常见的MapReduce面试题,帮助求职者更好地准备面试。


基本概念与配置
1. Map和Reduce的数量决定因素及配置方法
Map数量的决定因素:Map的数量主要由输入数据的切片(split)数量决定,每个切片会交由一个Map任务处理,而切片的数量则依赖于文件的大小和配置的块大小(blocksize)。
Reduce数量的配置方法:Reduce的数量可以直接通过配置文件或在代码中进行设置,它的数量会根据具体需求进行调整,以达到最优的处理效率。
切片的概念和影响:切片是处理数据的基本单位,每个切片通常处理等量的数据,但不会跨越文件边界,切片的大小通常等于块的大小,除非文件小于该块大小。
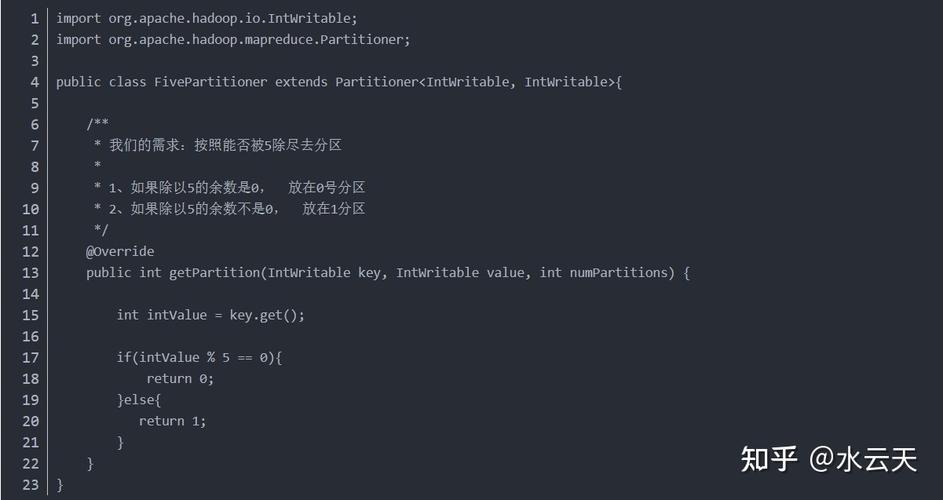
块大小的设定重要性:合理设置块大小可以优化Map任务的数量和处理速度,避免因单个任务处理过多数据而造成性能瓶颈。
优化技巧
2. MapReduce优化经验
设置合理的Map和Reduce个数:根据待处理的数据量和集群的规模,调整Map和Reduce的数量,以平衡负载并减少执行时间。
合理设置blocksize:通过调整HDFS的blocksize来改变切片的大小,进而影响到Map任务的数量和并行处理能力。
避免数据倾斜:通过预先分析数据分布,采用适当的Key设计,避免某些Reduce处理过多的数据,导致作业整体效率下降。
使用combine函数:在Map阶段使用combine函数可以对输出的键值对进行局部聚合,减少网络传输的数据量,从而提高整体性能。
数据压缩:对MapReduce的输入输出数据进行压缩,可以有效减少存储空间和网络传输的需求,加速数据处理过程。
高级特性
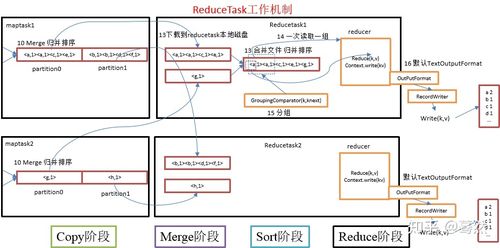
3. MapReduce的Copy和Merge阶段
Copy阶段的作用:在Reduce阶段开始前,Copy阶段负责从各个Map节点复制必要的数据到Reduce节点。
Merge阶段的操作:Merge阶段将这些数据合并,为后续的Reduce处理做准备,这包括内存和磁盘上的文件合并操作。
处理阈值的设置:对于数据的大小,如果超过一定阈值,则会直接写到磁盘上;较小的数据则可能直接在内存中处理。
通过上述点的讨论,可以看到MapReduce不仅仅是编程技术,更是一种涉及数据管理、系统配置和性能优化的综合技能,理解这些核心概念和技术将有助于在面试中展现出深厚的技术功底。
让我们看看一些常见问题及其答案,以便进一步巩固知识。
相关问题与解答
Q1: MapReduce如何处理大文件与小文件?
A1: MapReduce在处理不同大小的文件时,会根据文件大小和预设的块大小(blocksize)进行切片,对于大文件,它会切成多个块,每个块由一个Map任务处理,对于小文件,可能多个小文件会被打包成一个切片进行处理,这种机制确保了无论文件大小如何,系统都能高效地并行处理数据。
Q2: 如何防止MapReduce作业中的数据倾斜?
A2: 数据倾斜通常由于数据中的键分布不均匀导致某些Reduce节点负载过重,预防措施包括预先分析数据的键分布,调整Map或Reduce阶段的键值,或者使用Map端的combine函数和Reduce端的partitioner来均衡数据分配。
涵盖了MapReduce的核心概念、配置方法、优化技巧以及高级特性,并通过相关问题与解答加深理解,掌握这些知识点,将有助于在实际工作中更好地应用MapReduce技术,并在面试中展示出您的专业能力。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/591100.html
 微信扫一扫
微信扫一扫