

关于MapReduce流程的绘制,小编将详细展开步骤四:绘制流程页面,在这一步中,我们将重点介绍MapReduce的核心操作和数据处理过程,确保每个细节都能被清晰地理解和呈现。
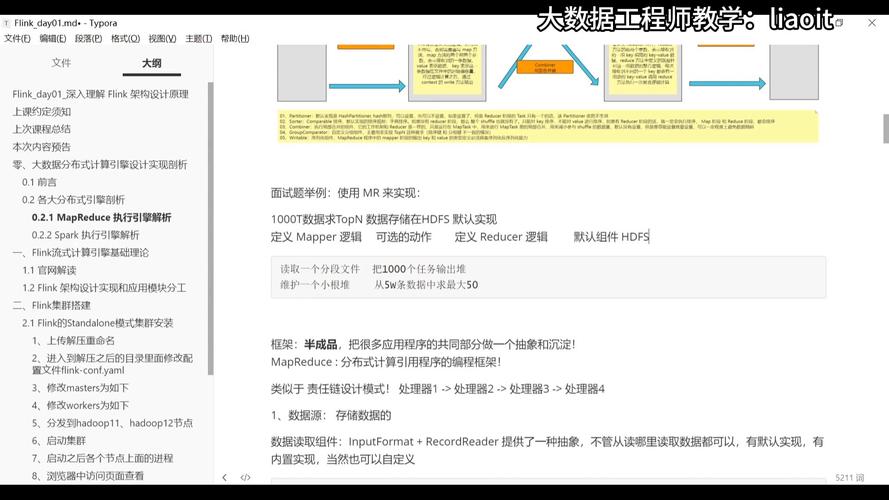

数据输入阶段
1. 数据读取
组件作用:在MapReduce流程的起始阶段,需要从Hadoop分布式文件系统(HDFS)中读取数据,此操作通常由TextInputFormat和LineRecordReader两个组件共同完成,TextInputFormat用于定义文件的输入格式,而LineRecordReader则负责按行读取数据。
操作细节:数据读取后,还需要进行适当的格式化处理,以便后续的Map阶段可以正确识别和处理数据。
2. 分片操作
定义与目的:分片是将大文件分割成多个小数据块,以便于并行处理,Hadoop默认每个分片大小为128MB。
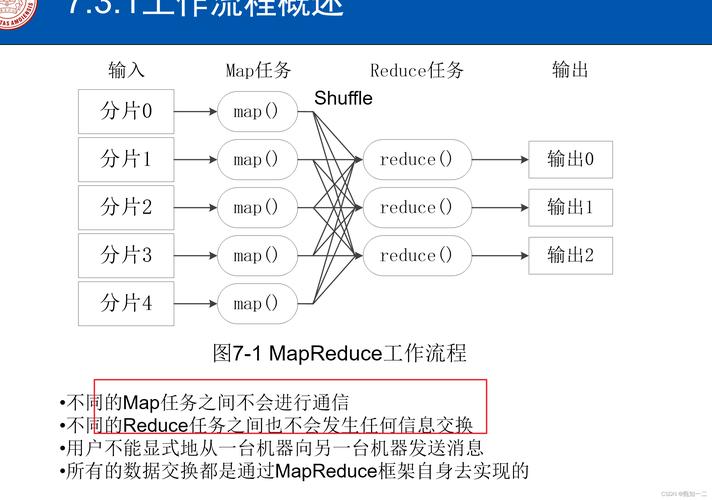
Map任务分配:每个分片会被分配给一个Map任务,该任务会处理分片中的每条记录,输出键值对<key, value>形式的中间数据,其中key是偏移量,value是行内容。
Map阶段
1. Map函数执行
Mapper的角色:Mapper的主要任务是接收输入数据,执行用户定义的map()函数,然后产出中间键值对。
业务逻辑实现:用户需在map()方法中实现具体的业务逻辑,这一部分是整个MapReduce流程中非常关键的自定义逻辑部分。
2. 数据分区与排序
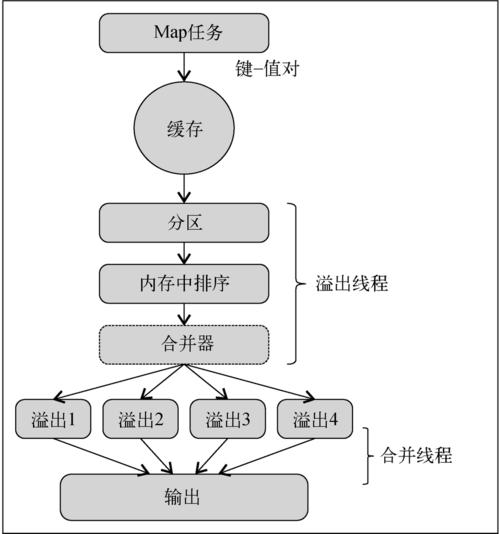
Shuffle过程:Map任务完成后,会进入Shuffle阶段,这个阶段主要负责数据的分区、排序和合并,这是为了确保Reducer能高效地接收到相关数据。
优化措施:可以通过调整环形缓冲区大小、采用合理的分区与排序策略来优化Shuffle过程,提高整体性能。
Reduce阶段
1. 数据整合
Reducer的任务:经过Map和Shuffle阶段后,Reducer开始工作,它接收来自不同Mapper的输出数据,并进行汇总或计算,最终输出结果。
业务逻辑实现:与Mapper类似,Reducer的业务逻辑也需要用户在reduce()方法中实现,这同样是自定义逻辑的部分。
2. 数据输出
结果存储:Reducer处理完数据后,会将结果写回到HDFS中,这样,所有客户端都可以访问到最终的计算结果。
相关问题与解答
1. MapReduce中Shuffle过程的作用是什么?
Shuffle过程是MapReduce中极为重要的一个环节,它负责将Map阶段的输出数据传输到Reduce阶段,这一过程包括数据的分区、排序和合并操作,确保了数据能够按照既定的规则聚合并传输,从而提高数据处理的效率和准确性。
2. 如何优化MapReduce的性能?
优化MapReduce性能可以从多个方面考虑:合理设定数据分片的大小,使用Combiner减少数据传输量,优化Shuffle过程中的缓冲区大小和存储方式等,根据实际需求合理设置Map和Reduce的任务数量也非常关键,这些都直接影响着程序的执行效率和资源利用率。
就是MapReduce流程中步骤四的详细解析,通过这些详细的步骤描述,可以帮助更好地理解MapReduce的内部工作机制及其在数据处理中的应用。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/591128.html
 微信扫一扫
微信扫一扫