

在大数据技术中,尤其是使用Hadoop框架进行数据处理时,MapReduce编程模型是核心之一,MapReduce过程中,数据序列化(Serialization)和反序列化(Deserialization)扮演着至关重要的角色,小编将深入探讨MapReduce中的数据序列化机制,并通过案例分析具体实现方法。

数据序列化基础
基本概念
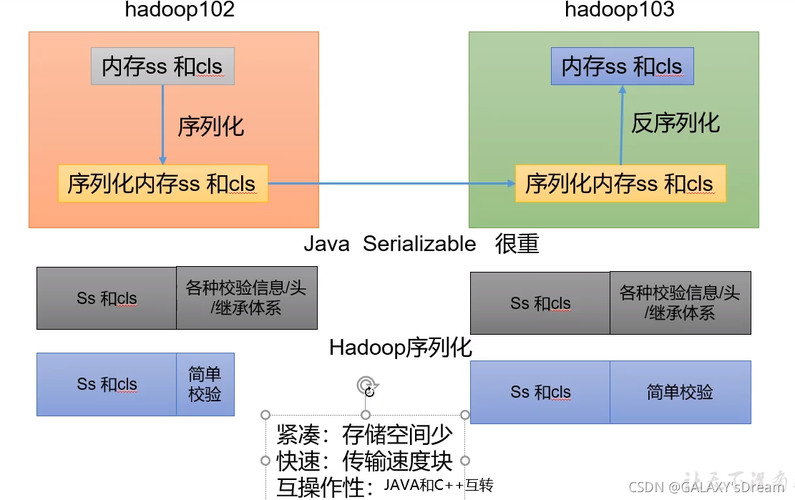
序列化是将内存中的对象转换成字节序列,以便于存储到磁盘和进行网络传输,反序列化则是相反的过程,即从字节序列恢复成原始对象。
为何需要序列化
持久化: 将内存中的数据保存到磁盘。
网络传输: 数据在网络中的传输需要以字节流的形式进行。
常用数据序列化类型
Java序列化: Java自带序列化框架,但性能较低。
Writable接口: Hadoop自开发的序列化机制,更高效。
MapReduce中的序列化
自定义序列化
在Hadoop MapReduce中,对于复杂的数据类型,开发者需要实现自己的序列化机制,这通常涉及到实现Writable接口,并重写write、readFields方法。
序列化与反序列化机制
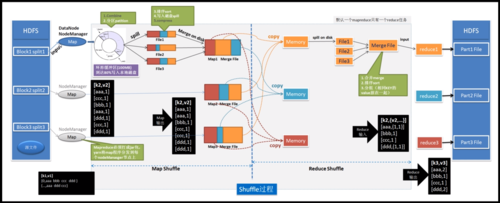
序列化: 在MapReduce的Shuffle阶段,需要将数据转换为字节流通过网络发送。
反序列化: 在Reduce阶段之前,需要将接收到的字节流转换回原始数据形式。
关键步骤
1、实现Writable接口: 自定义数据类型必须实现此接口。
2、重写write方法: 定义如何将对象字段写入输出流。
3、重写readFields方法: 定义如何从输入流读取字段,恢复对象状态。
序列化案例实操
需求分析
假设需要处理一个统计手机号流量的任务,该任务需要对大量的呼叫记录进行分析。
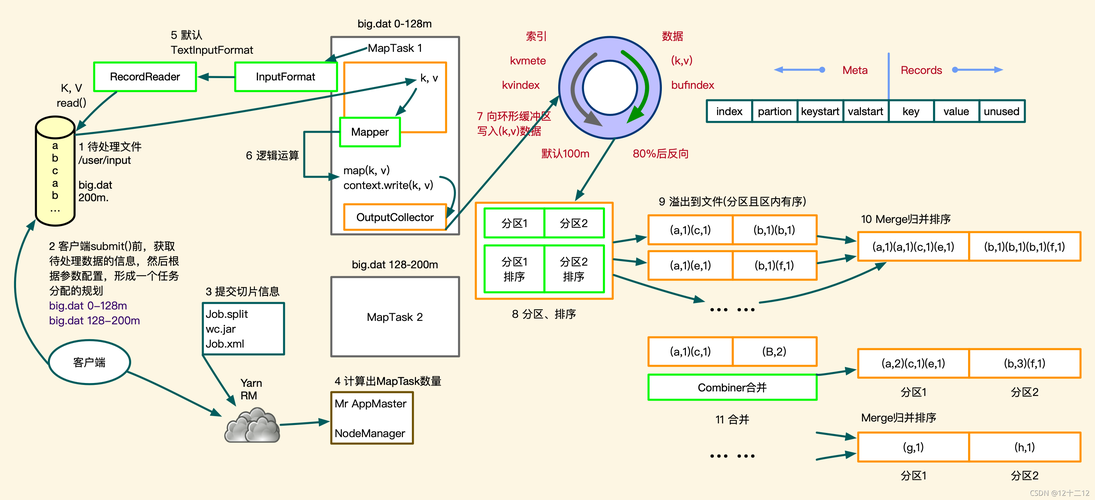
Map阶段
1、读取数据: 从HDFS读取呼叫记录文件。
2、解析与处理: 解析每条记录,提取手机号和流量信息。
3、序列化: 将提取的信息序列化,准备进行Shuffle操作。
Reduce阶段
1、反序列化: 对接收到的数据进行反序列化。
2、聚合计算: 对同一个手机号的流量进行累加。
3、输出结果: 将统计结果写出到HDFS。
相关问题与解答
Q1: 为什么Hadoop MapReduce选择自行开发序列化机制而非完全依赖Java自有序列化?
A1: Hadoop自开发了Writable接口作为序列化机制,主要是因为Java自带的序列化在性能和效率方面表现不佳,特别是在大规模数据处理时,Writable接口可以提供更高效、更灵活的序列化解决方案。
Q2: 自定义序列化类型时需要注意哪些问题?
A2:
确保正确实现write和readFields方法,保证数据的准确写入和读取。
注意处理可能出现的异常,确保序列化过程的稳定性。
考虑版本兼容性问题,尤其是在分布式环境中数据的一致性和可维护性。
通过以上内容,我们了解了在MapReduce模型中,数据序列化的重要性及其实现方式,自定义序列化虽然提高了灵活性和效率,但也增加了开发的复杂性,理解并正确实现序列化机制对于开发高效的MapReduce程序至关重要。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/591172.html
 微信扫一扫
微信扫一扫