

MapReduce 博客:深入理解 MapReduce

MapReduce 是一种编程模型,用于处理和生成大数据集,它是由谷歌在早期提出的,用于解决分布式系统上的数据处理问题,这个模型非常适合于大规模的数据操作,比如排序、搜索等,小编将详细介绍 MapReduce 的工作原理及其应用。
什么是 MapReduce?
MapReduce 是一个计算模型,它将复杂的任务分解为两个阶段:Map 和 Reduce。
Map: 负责对输入数据进行处理,生成一组中间键值对。
Reduce: 根据中间键值对的键进行归类,并对每一类执行相应的聚合操作。
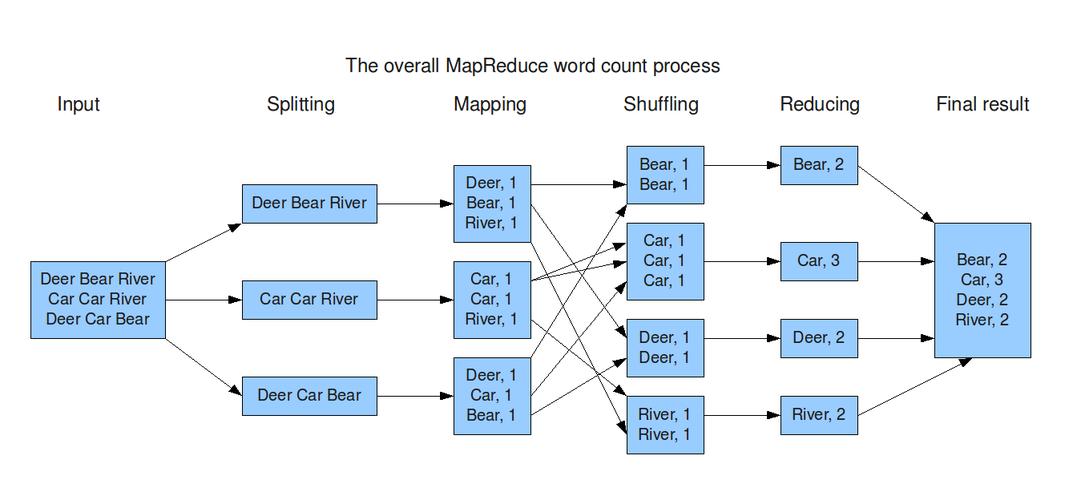
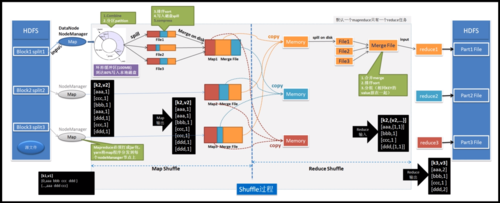
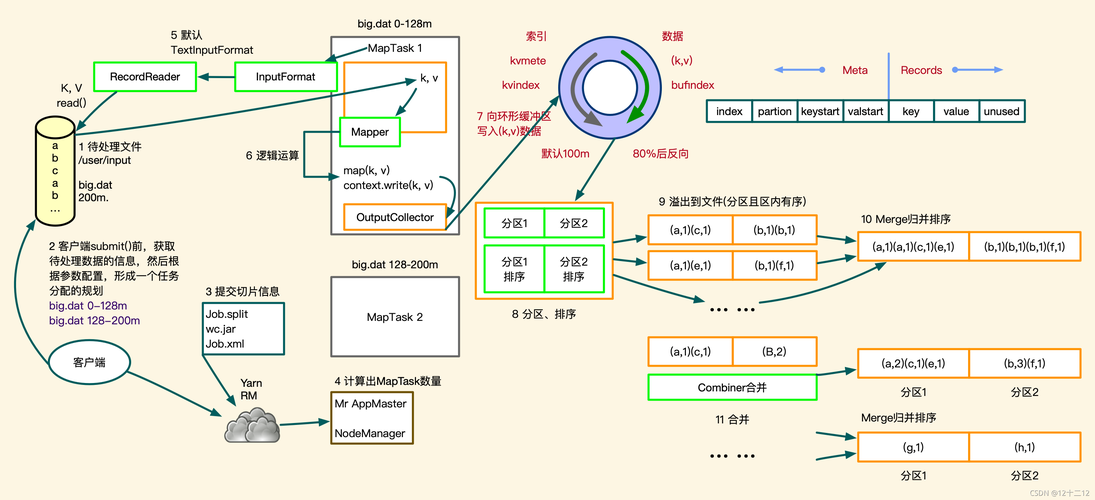
MapReduce 工作流程
| 步骤 | 描述 |
| 输入读取 | MapReduce 框架将输入文件切分成一定大小的片段(splits)。 |
| Map 阶段 | Map 函数处理每一个输入片段,输出中间键值对。 |
| Shuffle 和 Sort | 框架将具有相同键的值组织在一起,并传递给 Reduce 函数。 |
| Reduce 阶段 | Reduce 函数对每个键的所有值进行处理,输出最终结果。 |
| 输出写入 | 最终结果被写回到文件系统。 |
MapReduce 的优点
可扩展性: 可以在数千台计算机上并行处理大量数据。
容错性: 能够自动处理失败节点的任务重试。
简单性: 程序员只需编写 Map 和 Reduce 函数。
MapReduce 的局限性
实时处理: 不适合需要实时响应的场景。
效率问题: 对于小数据集或需要频繁读写的操作不够高效。
灵活性: 对于某些复杂算法,使用 MapReduce 可能过于繁琐。
MapReduce 的实际应用案例
日志分析: 处理服务器生成的大量日志文件,统计访问次数等信息。
大规模排序: 如对互联网数据进行排序,生成排名列表等。
机器学习: 利用 MapReduce 来并行处理训练数据和模型参数更新。
相关问题与解答
Q1: MapReduce 适合处理哪些类型的任务?
A1: MapReduce 特别适合处理数据密集型任务,比如数据分析、日志处理、大规模排序等,它能够有效处理那些可以分解为独立子任务的问题。
Q2: 如果我想提高 MapReduce 作业的执行效率,有哪些优化策略?
A2: 一些常见的优化策略包括:
合理设置 Map 和 Reduce 的数量: 根据集群大小和作业特性调整。
优化数据序列化方法: 使用高效的序列化库减少数据传输量。
压缩中间数据: 减少网络传输和磁盘存储的压力。
合理划分输入数据: 确保数据均匀分配到各个 Map 任务。
优化算法逻辑: 减少不必要的计算和数据读写操作。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/591248.html
 微信扫一扫
微信扫一扫