


简介
mapreduce是一种编程模型,用于大规模数据集(大于1tb)的并行运算,其概念“map(映射)”和“reduce(归约)”是函数式编程语言中常见的高阶函数,在mapreduce模型中,它们被用作处理数据的关键步骤,本文将详细介绍如何使用mapreduce进行文本统计分析。
map阶段
输入数据
假设我们有一个大型的文本数据集,我们需要从中统计各种文本分析指标,如词频、句子长度等。
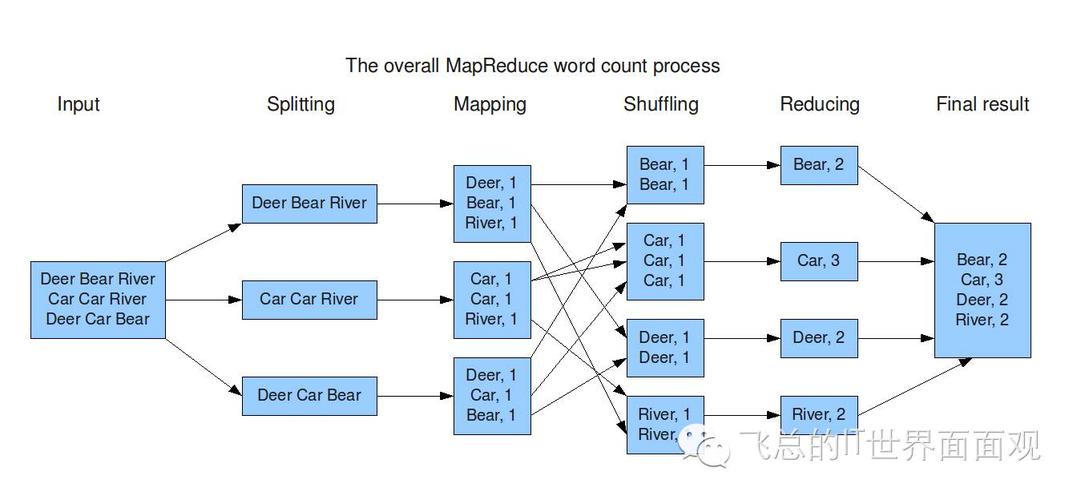
map函数设计
map函数的任务是将输入数据(文本)分割成小块,并为每一块生成键值对,如果我们想统计单词的频率:
输入: 一行文本
输出: 一个包含单词及其出现次数(初始为1)的键值对列表。
map阶段示例
def map(text):
# 假设text已经分词
for word in text:
emit(word, 1)
reduce阶段
reduce函数设计
reduce函数接收来自map阶段的输出作为输入,并聚合具有相同键的值,在我们的例子中,它将计算每个单词的总频率。
reduce阶段示例
def reduce(word, values):
# values是一个整数列表,代表该单词的出现次数
return (word, sum(values))
组合结果
最终的结果将是所有单词及其总频率的列表,这个结果可以用于进一步的分析,比如找出最常见的单词,或生成词云等。
相关问题与解答
q1: mapreduce如何确保处理大量分布式数据?
a1: mapreduce通过将作业分解到多个节点上来处理大量分布式数据,每个节点执行map任务来处理一部分数据,然后reduce任务汇总这些部分的结果,这个过程涉及数据的分区、复制和容错,以确保大规模数据处理的可靠性和效率。
q2: 如何优化mapreduce作业的性能?
a2: 优化mapreduce作业性能的方法包括:
确保map和reduce函数尽可能高效,避免不必要的计算。
调整mapreduce作业的配置参数,例如内存配置、并发任务数等。
使用压缩技术来减少网络传输的数据量。
选择合适的数据结构,以最小化存储和处理开销。
预先对数据进行排序和分区,以改善负载均衡和减少数据传输。
是使用mapreduce框架进行文本统计分析的基本流程和一些常见问题的解答,通过适当的设计和优化,mapreduce可以在处理海量文本数据时提供有效的解决方案。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/591312.html
 微信扫一扫
微信扫一扫