

MapReduce写入HBase


MapReduce是一种编程模型,用于处理和生成大数据集,HBase是一个分布式、可扩展的大数据存储系统,它基于Google的BigTable设计,小编将介绍如何使用MapReduce将数据写入HBase,并从HBase读取数据再写入HBase的过程。
步骤1:配置HBase环境
确保你已经正确安装和配置了HBase,你需要设置HBase的环境变量,包括HBASE_HOME和HADOOP_HOME等。
步骤2:编写MapReduce程序
写入HBase
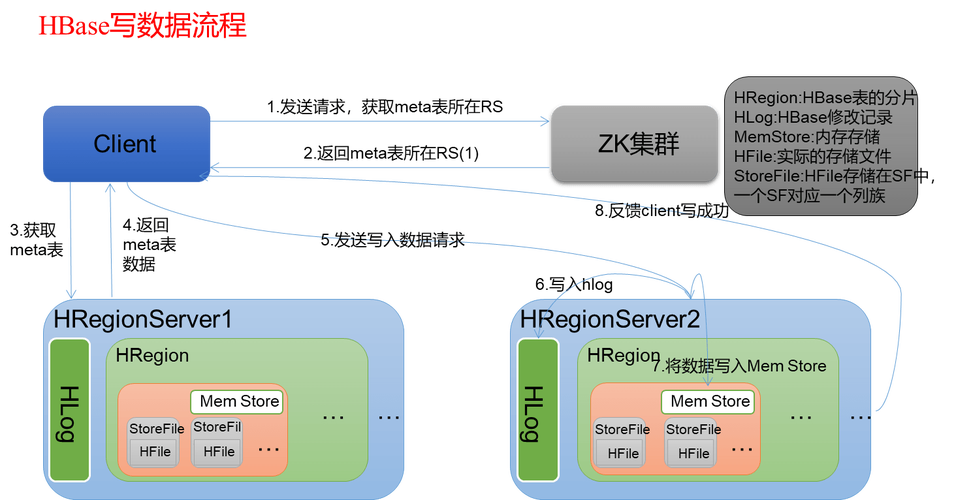
创建一个Java类,继承TableMapper和TableReducer,分别实现map和reduce方法,以下是一个简单的示例:
import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.output.TableOutputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; public class HBaseWriteExample { public static class WriteMapper extends TableMapper<Text, IntWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 解析输入数据,例如每行一个键值对 String[] parts = value.toString().split("\t"); String rowKey = parts[0]; int count = Integer.parseInt(parts[1]); // 输出键值对到HBase表 Put put = new Put(Bytes.toBytes(rowKey)); put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("count"), Bytes.toBytes(count)); context.write(new ImmutableBytesWritable(rowKey.getBytes()), put); } } public static class WriteReducer extends TableReducer<Text, IntWritable, ImmutableBytesWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { // 这里不需要reduce操作,因为每个键只有一个值 } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.set("hbase.zookeeper.quorum", "localhost"); // 设置ZooKeeper地址 conf.set("hbase.zookeeper.property.clientPort", "2181"); // 设置ZooKeeper端口 conf.set(TableOutputFormat.OUTPUT_TABLE, "my_table"); // 设置输出表名 Job job = Job.getInstance(conf, "HBase Write Example"); job.setJarByClass(HBaseWriteExample.class); job.setMapperClass(WriteMapper.class); job.setReducerClass(WriteReducer.class); job.setOutputFormatClass(TableOutputFormat.class); job.setInputFormatClass(TextInputFormat.class); FileInputFormat.addInputPath(job, new Path(args[0])); // 设置输入路径 System.exit(job.waitForCompletion(true) ? 0 : 1); } }
从HBase读取数据再写入HBase
要从HBase读取数据并再次写入HBase,你可以使用类似的方法,但需要修改mapper和reducer的逻辑,以下是一个示例:
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.TableOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.TableInputFormat;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseReadAndWriteExample {
public static class ReadMapper extends TableMapper<Text, IntWritable> {
@Override
protected void map(ImmutableBytesWritable rowKey, Result result, Context context) throws IOException, InterruptedException {
// 从HBase表中读取数据
byte[] valueBytes = result.getValue(Bytes.toBytes("cf"), Bytes.toBytes("count"));
int count = Bytes.toInt(valueBytes);
// 输出键值对到HBase表
Put put = new Put(rowKey.get());
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("count"), Bytes.toBytes(count + 1)); // 增加计数器
context.write(rowKey, put);
}
}
public static class ReadReducer extends TableReducer<Text, IntWritable, ImmutableBytesWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 这里不需要reduce操作,因为每个键只有一个值
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "localhost"); // 设置ZooKeeper地址
conf.set("hbase.zookeeper.property.clientPort", "2181"); // 设置ZooKeeper端口
conf.set(TableOutputFormat.OUTPUT_TABLE, "my_table"); // 设置输出表名
conf.set(TableInputFormat.INPUT_TABLE, "my_table"); // 设置输入表名
Job job = Job.getInstance(conf, "HBase Read and Write Example");
job.setJarByClass(HBaseReadAndWriteExample.class);
job.setMapperClass(ReadMapper.class);
job.setReducerClass(ReadReducer.class);
job.setOutputFormatClass(TableOutputFormat.class);
job.setInputFormatClass(TableInputFormat.class);
TableMapReduceUtil.initTableReducerJob(job); // 初始化TableReducerJob
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
问题与解答栏目
问题1:如何确保MapReduce作业成功运行?
解答1: 确保MapReduce作业成功运行的关键因素包括:
确保HBase集群正常运行并且可以从你的应用程序访问。
检查作业的配置是否正确,包括输入和输出表的名称、ZooKeeper的地址和端口等。
确保输入数据的格式正确,以便能够被正确地解析和处理。
检查代码中是否存在语法错误或逻辑错误。
监控作业的日志以查找可能的错误信息。
如果作业失败,请查看任务追踪器(TaskTracker)或资源管理器(ResourceManager)的日志以获取更多详细信息。
问题2:如何处理MapReduce作业中的异常情况?
解答2: 在MapReduce作业中处理异常情况的方法包括:
捕获并处理可能出现的异常,例如IO异常、网络异常等,可以使用trycatch语句来捕获这些异常,并在catch块中进行适当的处理,如记录错误日志或发送警报通知。
在作业配置中启用容错机制,例如设置mapreduce.map.maxattempts和mapreduce.reduce.maxattempts参数来指定任务的最大尝试次数,这样,如果某个任务失败,它将自动重试直到达到最大尝试次数。
对于可能导致作业失败的关键操作,可以添加额外的验证和错误检查逻辑,以确保数据的完整性和一致性。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/591416.html
 微信扫一扫
微信扫一扫