

MapReduce单词共现与关键词抽取
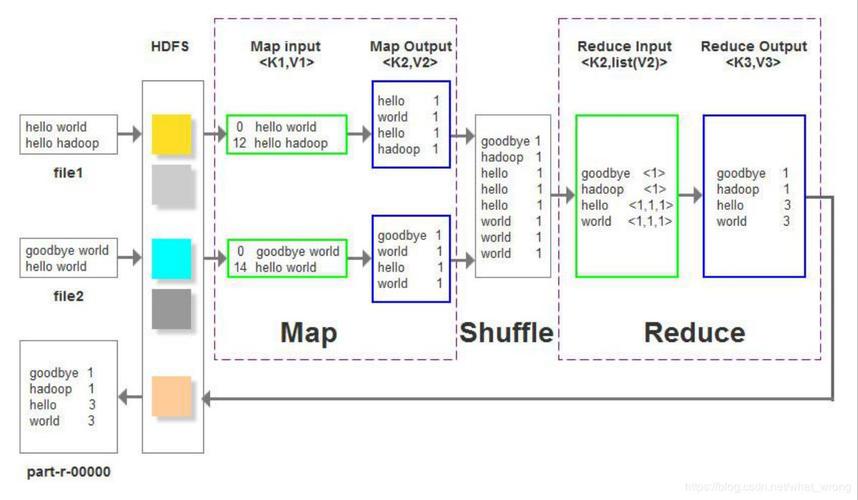

MapReduce模型在处理大规模数据集时非常高效,特别是在自然语言处理和文本分析领域,单词共现和关键词抽取是这一领域中的重要技术,它们通过分析文本中单词的出现模式来揭示潜在的语义结构和关键信息,本文将深入探讨如何使用MapReduce框架来实现单词共现矩阵的构建和基于此的关键词抽取。
共现矩阵的构建
定义共现窗口:
共现窗口定义为连续出现的两个单词,对于句子 "The quick brown fox jumps over the lazy dog",其共现窗口包括 ("quick", "brown"), ("brown", "fox") 等。
Map阶段:
Map阶段的主要任务是读取文本数据并构建单词对,Map函数会遍历每个文档的所有单词,并为每个单词对 (w, u) 发射一个出现计数(初始为1),以下是Map阶段的伪代码示例:
class Mapper {
method Map(docid did, doc d) {
for all word w in d {
for all word u in Window(w) {
Emit(pair(w, u), 1)
}
}
}
}
Reduce阶段:
在Reduce阶段,系统会根据Map阶段发射的键值对进行排序和聚合,Reduce函数将对相同键的值进行汇总,从而得到每个单词对的总共现次数。
class Reducer {
method Reduce(pair(w, u), list of counts) {
sum = 0
for each count in list of counts {
sum += count
}
Emit(pair(w, u), sum)
}
}
实现细节:
小文件和大文件处理: 当处理非常大的文本集时,MapReduce作业可能会涉及大量的小文件,这会导致处理效率低下,因此需要采用适当的策略如合并输入文件(combining input files)或使用合适的InputFormat来优化。
自定义InputFormat: 根据数据的特性和需求,可以自定义InputFormat 来更好地描述数据的格式和分割逻辑,从而提高处理的效率和精确度。
关键词抽取
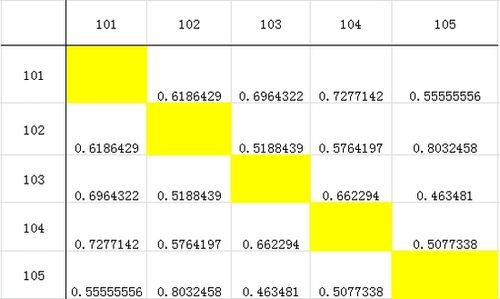
构建相似度矩阵:
一旦共现矩阵构建完成,接下来可以结合相似度系数(如余弦相似度)来构建一个相似度矩阵,这个相似度矩阵可以用于衡量不同单词之间的关联强度,有助于识别文本中的关键词。
ZScore计算:
通过对相似度矩阵应用 ZScore 标准化,可以进一步突出那些与多数其他词共现频率显著不同的词,这些词往往是文本中的关键词,因为它们在文本中扮演着核心角色。
相关问题与解答
Q1: MapReduce处理大规模文本数据有哪些优势?
A1: MapReduce能够分布式处理数据,这使得它非常适合大规模数据集,它可以并行处理数据的不同部分,大大减少了处理时间,由于其容错性,系统可以自动处理节点失败的问题,保证数据处理的稳定性和可靠性。
Q2: 如何优化MapReduce作业的性能?
A2: 优化MapReduce作业性能的方法包括:合理设置共现窗口的大小、选择合适的数据传输和存储格式、以及适当调整Map和Reduce任务的数量,考虑数据的本地化也可以减少网络传输的开销,提高作业执行速度。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/591472.html
 微信扫一扫
微信扫一扫