

MapReduce不等值Join
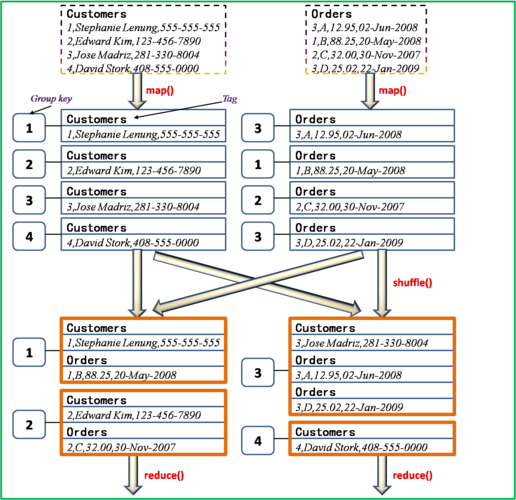
MapReduce是一种编程模型,用于处理和生成大数据集,在MapReduce中,不等值join是一种常见的操作,它允许我们将两个不同键的数据集合合并在一起,不等值join是指在连接过程中,两个数据集中的主键(或关键列)可能具有不同的值范围或类型。
步骤
1、Map阶段:将输入数据分成多个独立的块,并对每个块进行处理,对于每个记录,将其主键作为key,整个记录作为value输出。
2、Shuffle阶段:将所有具有相同key的记录分组在一起,由于主键可能不同,所以这一步可能会产生大量的组。
3、Reduce阶段:对每个组中的记录进行迭代,并将它们与另一个数据集中的记录进行比较,如果满足连接条件(两个记录的关键列相等),则将它们组合在一起。
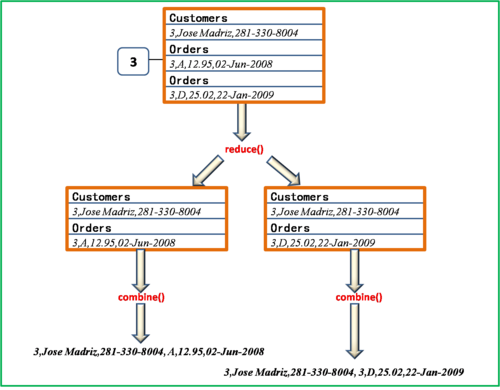
示例代码
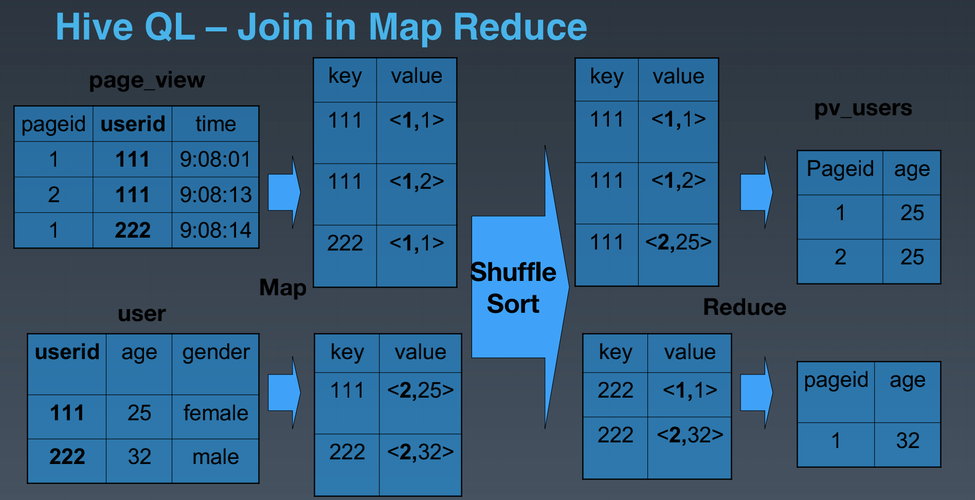
假设我们有两个数据集A和B,它们分别有如下结构:
数据集A:{id, name}
数据集B:{id, age}
我们希望根据id字段将这两个数据集连接起来,以下是一个简单的MapReduce不等值join的伪代码示例:
def map(record):
# 提取记录的关键列
key = record['id']
value = record
emit(key, value)
def reduce(key, values):
# 获取来自数据集A和B的所有相关记录
records_A = [v for v in values if 'name' in v]
records_B = [v for v in values if 'age' in v]
# 执行连接操作
for record_A in records_A:
for record_B in records_B:
if record_A['id'] == record_B['id']:
# 合并记录并输出结果
result = {record_A,record_B}
emit(result)
相关问题与解答
问题1:MapReduce不等值Join的性能如何?
解答:MapReduce不等值Join的性能取决于多种因素,包括数据的大小、分布、连接条件以及集群的配置等,在某些情况下,不等值Join可能会导致大量的数据传输和计算开销,从而影响性能,为了提高性能,可以考虑使用分区技术、索引或其他优化策略来减少不必要的数据传输和计算。
问题2:如何在MapReduce中实现更复杂的不等值Join操作?
解答:在MapReduce中实现更复杂的不等值Join操作通常需要更多的逻辑和技巧,一种方法是使用多个MapReduce作业链来完成连接操作,可以使用一个MapReduce作业来过滤出符合条件的记录,然后使用另一个作业来进行实际的连接操作,还可以考虑使用分布式数据库系统或大数据处理框架(如Apache Spark)来实现更复杂的不等值Join操作,这些框架提供了更高级的API和优化策略来处理这种类型的任务。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/591480.html
 微信扫一扫
微信扫一扫 