

MapReduce 拆分_批次拆分
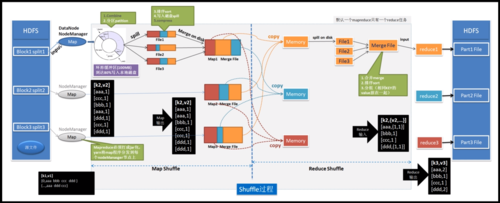

MapReduce是一种编程模型,用于处理和生成大数据集的并行算法,在MapReduce中,数据被分成多个批次进行处理,每个批次被称为一个切片(slice),小编将详细介绍MapReduce中的批次拆分过程。
1. 数据分片
在MapReduce框架中,输入数据首先会被分割成多个独立的块或片段,这些片段被称为切片(slices),切片的大小通常是固定的,例如64MB或128MB,切片的大小可以根据实际需求进行调整,但通常需要权衡内存使用和磁盘I/O之间的平衡。
2. Mapper阶段
一旦数据被切片,每个切片都会被分配给一个Mapper任务,Mapper的任务是读取其分配的数据片段,并对每个记录执行map函数,map函数的输出是一个键值对(keyvalue pair),其中键是唯一的标识符,值是与该键相关的数据。
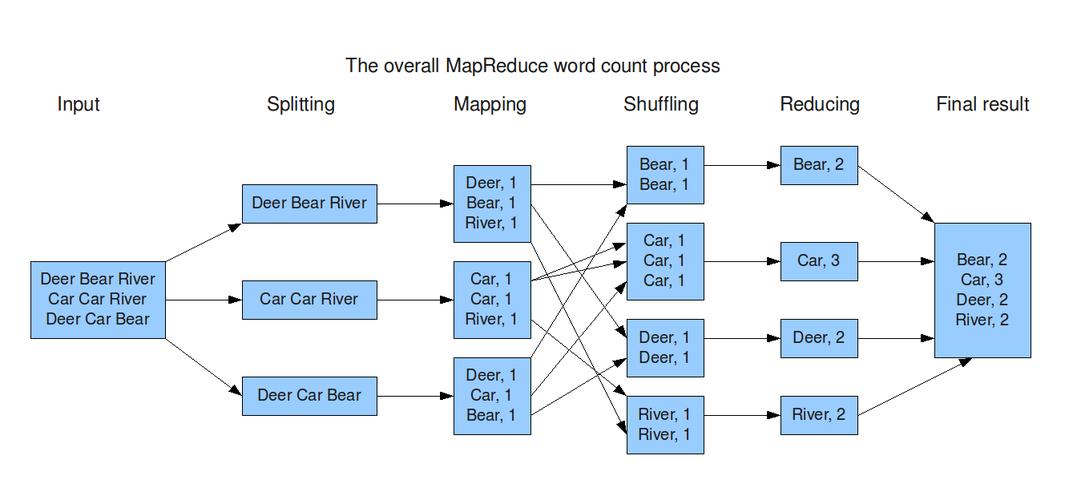
3. Shuffle阶段
在Mapper阶段完成后,所有的键值对会被收集起来,并根据键进行排序,这个过程称为Shuffle,排序后的键值对会被传递给Reducer任务。
4. Reducer阶段
Reducer任务接收到所有具有相同键的键值对,并对它们执行reduce函数,reduce函数的目的是将具有相同键的所有值合并成一个单一的输出值,Reducer会输出一组键值对作为结果。
5. 结果汇总
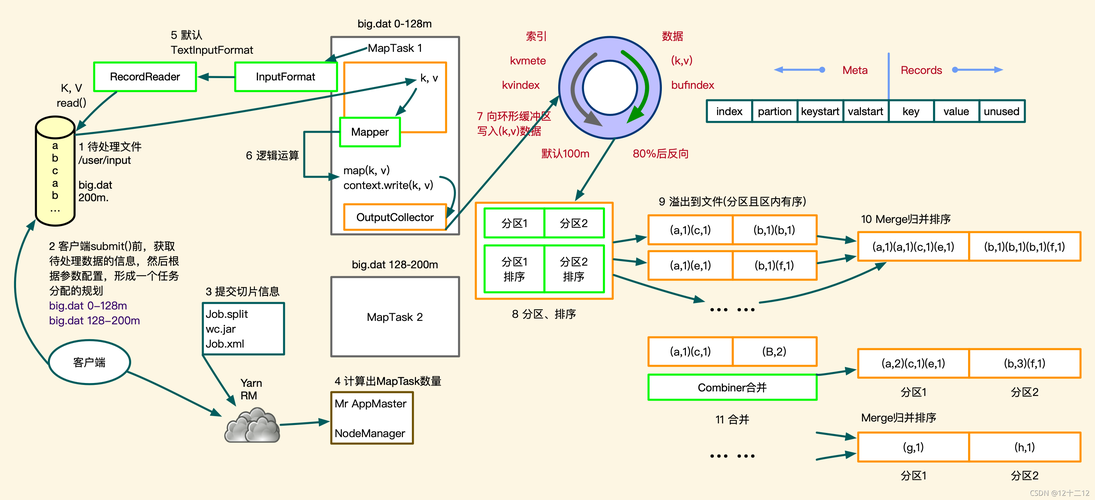
所有Reducer任务完成后,它们的输出将被汇总并形成最终的结果集。
相关问题与解答:
问题1: 为什么MapReduce需要将数据分片?
答案1: MapReduce通过将数据分片来提高处理效率,分片允许数据在不同的节点上并行处理,从而充分利用集群的计算能力,分片还可以减少单个节点上的内存压力,因为每个节点只需要处理一部分数据。
问题2: 在MapReduce中,如何确定切片的大小?
答案2: 切片的大小通常由系统管理员根据实际需求和硬件配置来确定,较大的切片可以减少网络传输的次数,从而提高整体性能;而较小的切片可以更好地利用内存资源,减少内存溢出的风险,最佳切片大小取决于具体的应用场景和硬件环境。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/591528.html
 微信扫一扫
微信扫一扫