

MapReduce和Spark Shuffle异常处理深入解析
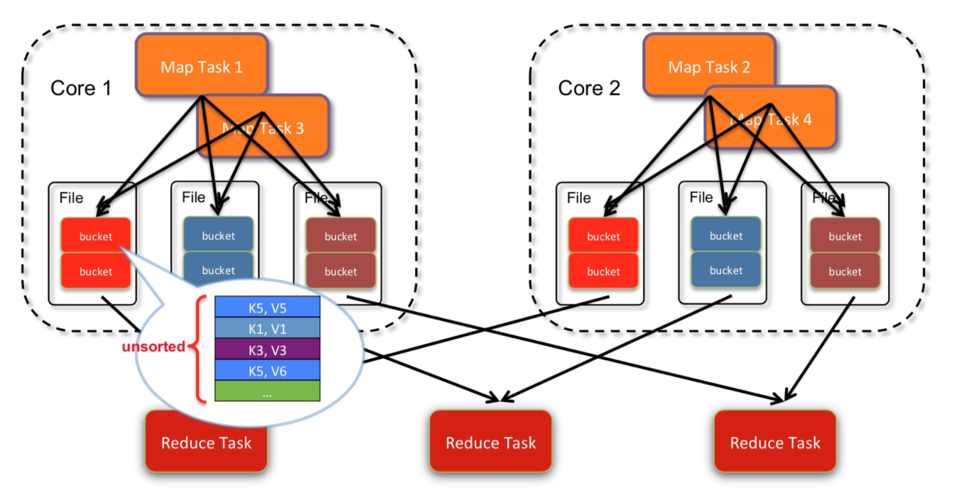

Shuffle概念及重要性
1. Shuffle定义:
MapReduce中的Shuffle:在MapReduce框架中,Shuffle是指将Map阶段的输出传输到Reduce阶段作为输入的过程,它负责对数据进行分组和传输,确保数据正确送达对应的Reduce任务。
Spark中的Shuffle:在Spark中,Shuffle是连接每一段数据处理操作的桥梁,主要在转换算子如groupByKey,reduceByKey等操作中发挥作用,用于重新分区和/或排序数据。
2. Shuffle过程的重要性:
数据重组与传递:Shuffle过程是实现数据从Map任务向Reduce任务转移的必经之路,对于数据的准确重组和高效传输至关重要。
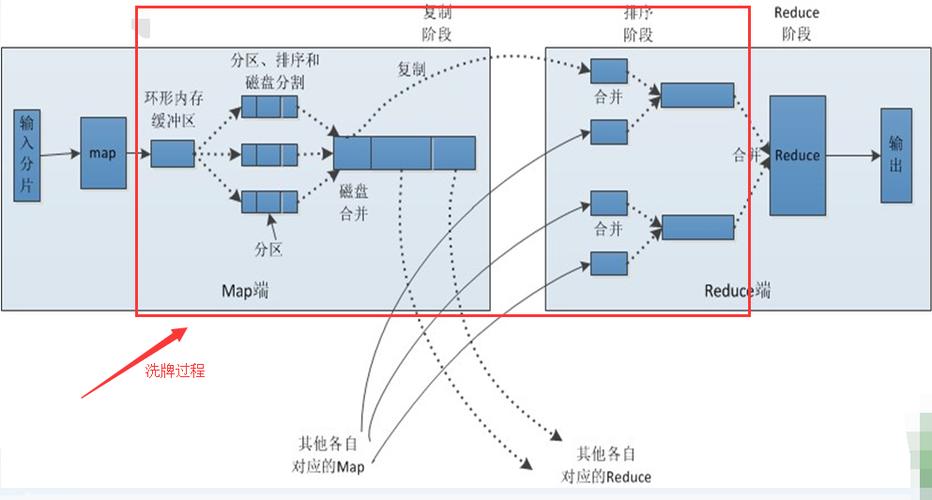
影响性能瓶颈:Shuffle过程往往是数据处理的一个瓶颈,优化Shuffle的性能直接影响整个程序的运行效率。
Shuffle异常类型及原因
1. 数据倾斜:
倾斜原因:当某个或某些key的数据量远大于其他key时,会导致部分任务执行时间延长,从而影响整体的处理速度。
影响:数据倾斜可以导致资源的不合理分配和使用,增加任务完成的总时间。
2. 配置不当:
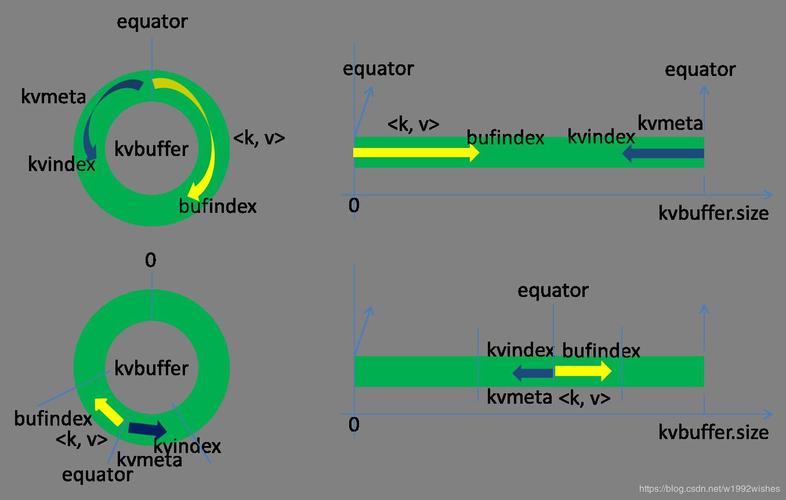
网络和磁盘I/O:Shuffle过程中频繁的网络传输和磁盘读写可能导致性能问题。
内存溢出:不合理的内存配置可能引起数据处理时的内存溢出错误。
Shuffle异常处理方法
1. 参数调优:
设置合适的Sort Shuffle阈值:通过调整spark.shuffle.sort.bypassMergeThreshold参数(默认值200),可以优化大数据量处理时的性能。
合理配置内存和CPU资源:根据作业的需求,合理设置Spark资源配置,避免资源争用和性能瓶颈。
2. 选择适当的Shuffle Manager:
HashShuffleManager与SortShuffleManager:根据具体的使用场景选择合适的Shuffle Manager,SortShuffleManager通常更适用于大数据集的处理,它可以有效减少磁盘I/O和数据移动的开销。
3. 代码优化:
避免数据倾斜:通过调整代码逻辑,例如增加并行度、使用随机key等方法减轻数据倾斜的影响。
利用Tungsten优化:利用Spark的Tungsten项目优化Shuffle操作,提高数据处理效率。
常见问题解答
1. Shuffle过程中常见的性能瓶颈有哪些?
网络传输:大量的数据传输可能导致网络拥堵,延迟增加。
磁盘I/O:过多的磁盘读写操作会严重影响性能。
内存压力:数据处理过程中可能会因为数据量大导致内存溢出。
2. 如何选择合适的Shuffle Manager?
根据数据大小:对于小数据集,可以考虑使用HashShuffleManager;对于大数据集,推荐使用SortShuffleManager。
考虑资源使用情况:SortShuffleManager虽然减少了磁盘I/O,但可能会使用更多CPU和内存资源。
本文详细探讨了MapReduce和Spark中Shuffle过程的异常处理策略,了解Shuffle的基本概念及其在数据处理中的重要性是基础,随后,文中分析了Shuffle过程中可能出现的异常类型及其原因,并提供了针对性的处理方法,包括参数调优、选择合适的Shuffle Manager以及代码层面的优化建议,希望这些信息能帮助您更好地理解和应对在使用MapReduce和Spark时可能遇到的Shuffle相关问题。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/591564.html
 微信扫一扫
微信扫一扫