

MapReduce在图片处理中的应用
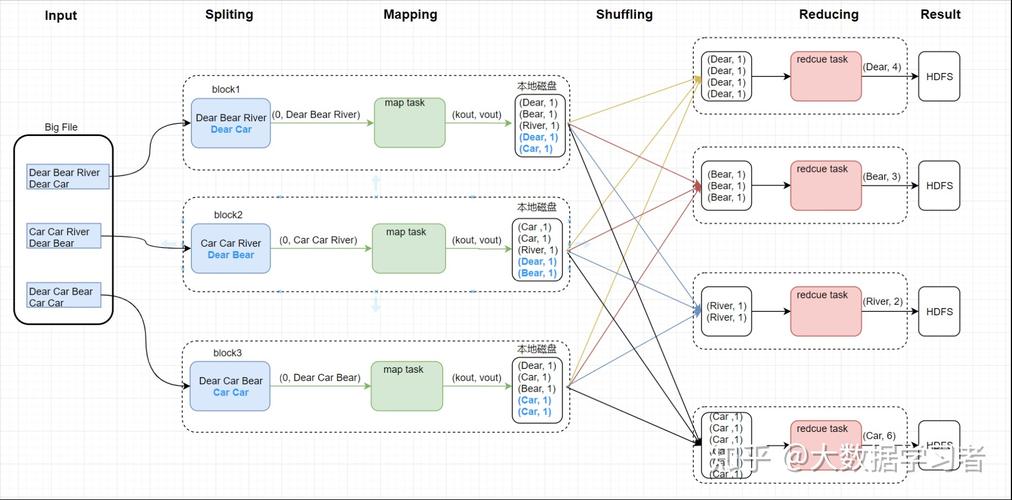

MapReduce模型是一种在大规模数据集中处理数据的编程框架,由两个基本阶段组成:Map阶段和Reduce阶段,在Map阶段,数据被分解成小任务,由多个计算节点并行处理;在Reduce阶段,各个节点处理的结果被整合得到最终结果,这种模型特别适合于图像处理领域,可以有效地处理和分析大规模的图像数据集,将深入探讨MapReduce在图像处理领域的应用。
1、图像预处理的MapReduce实现
Map阶段主要进行图像的基本操作,如裁剪、调整大小、去噪等,每个计算节点独立处理一部分图像。
Reduce阶段则汇总处理后的图像数据,准备进行下一步的特征提取或分类。
2、特征提取的分布式处理
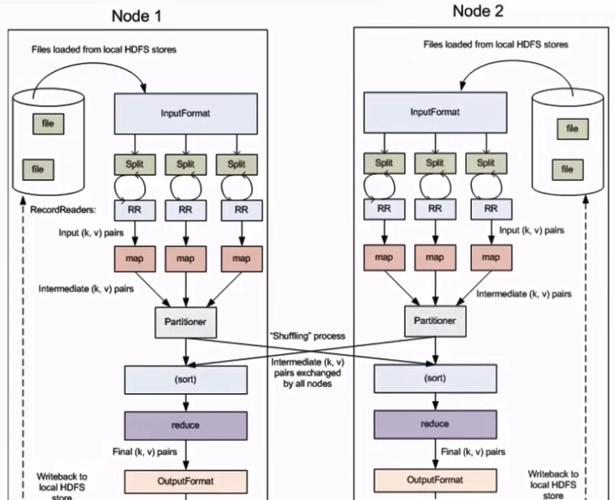
在Map阶段,各节点对其分配到的图像子集执行特征提取算法,如边缘检测、角点检测等。
Reduce阶段则聚焦于汇总所有图像的特征数据,为后续的图像分析提供数据支持。
3、图像分类与目标检测
通过Map阶段的分布式计算,对图像数据应用分类或目标检测算法,识别图像内容。
Reduce阶段整合各节点的识别结果,输出最终的分类标签或目标位置信息。
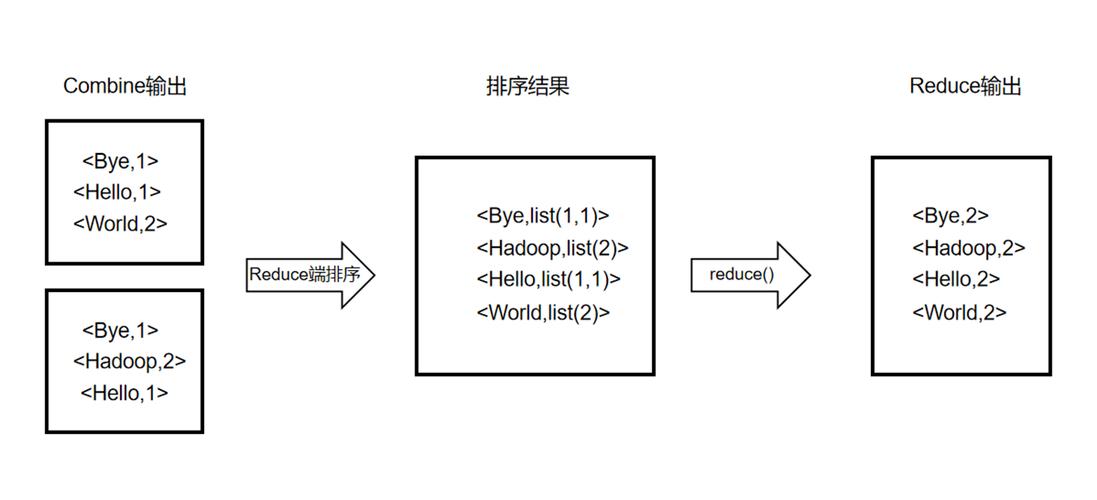
4、图像分析与模式识别
在Map阶段,进行更复杂的图像分析任务,比如模式识别,涉及图像内容的深度分析和理解。
Reduce阶段则将所有图像的分析结果综合起来,提供对整体数据集的洞察。
5、性能优化与资源管理
在处理过程中,优化算法和资源分配是关键,确保计算效率和负载均衡。
结合其他大数据技术(如Hadoop),可以进一步提升图像处理任务的性能和扩展性。
相关问题与解答
Q1: MapReduce如何处理大规模图像数据集?
Q2: MapReduce模型在图像处理中的优势是什么?
Q1: 在处理大规模图像数据集时,MapReduce首先将数据集分成多个小的任务,每个任务由一个Map函数处理,这些函数可以在不同的计算节点上并行执行,比如进行图像裁剪、缩放等预处理操作,之后,Reduce函数会汇总这些操作的结果,进行最终的整合,比如特征汇总、结果统计等。
Q2: MapReduce模型在图像处理中的主要优势在于其高效的并行处理能力和弹性的资源管理,它能够处理远超单机处理能力的大规模图像数据集,同时通过分布式计算显著缩短处理时间,MapReduce容错性好,能自动处理节点失败的问题,保证任务的顺利完成。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/591568.html
 微信扫一扫
微信扫一扫