

MapReduce和Pipeline都是处理大数据的编程模型。MapReduce通过映射(Map)和归约(Reduce)两个阶段来处理数据,适用于大规模数据集的并行运算。而CodeArts Pipeline是华为云的一种数据编排服务,它允许用户以可视化方式设计数据处理流程,简化了数据工程的实施和管理。两者都旨在提高数据处理的效率和可扩展性,但应用场景和操作方式有所不同。
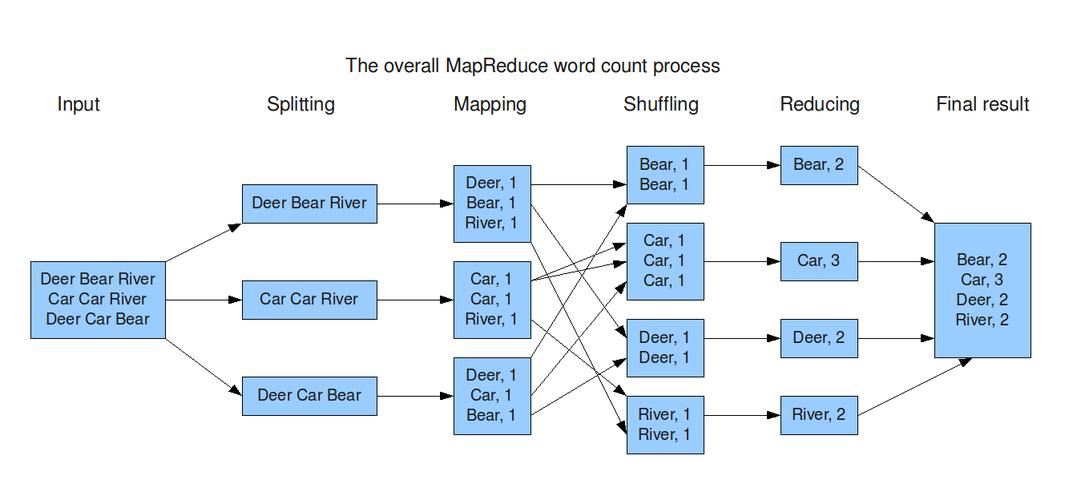
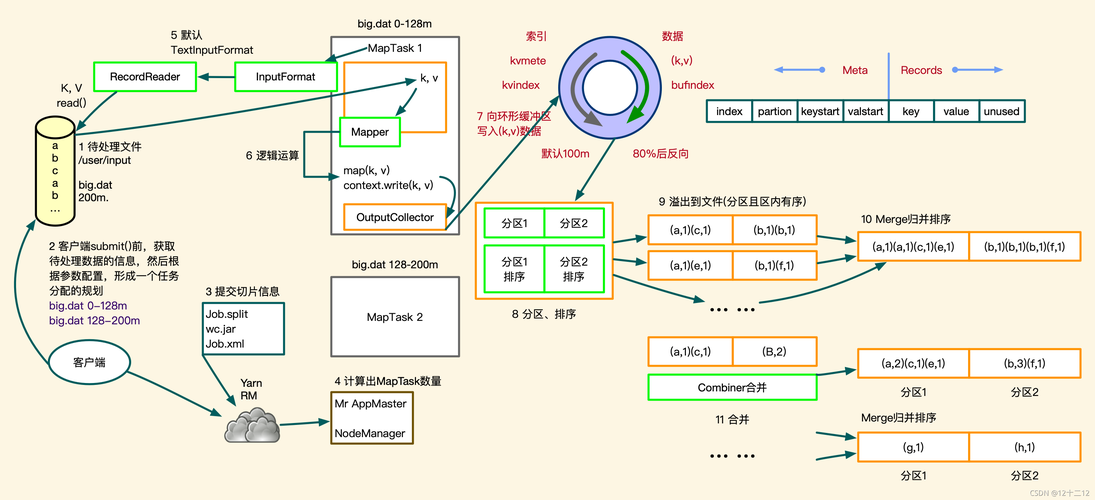
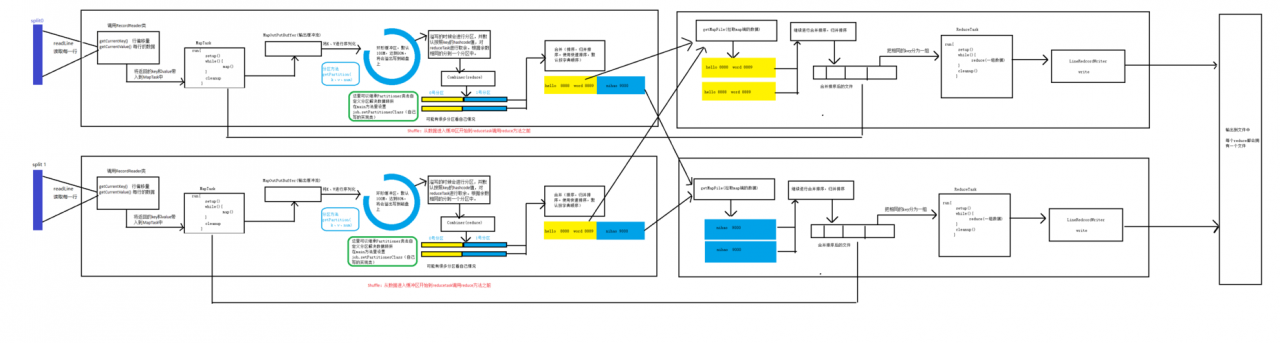
MapReduce是一种编程模型,用于处理和生成大数据集(大于1TB),它可以使用大量的计算资源在多个节点上并行处理数据,MapReduce模型将任务分为两个阶段:Map阶段和Reduce阶段。

(图片来源网络,侵删)
Map阶段
Map阶段的任务是处理输入数据并生成中间键值对,Map函数接收输入数据,并将其转换为一组中间键值对,这些键值对被缓存在内存中,并在需要时写入磁盘。
def map(key, value):
# 处理输入数据并生成中间键值对
...
Shuffle阶段
Shuffle阶段是MapReduce的一个关键步骤,它将Map阶段的输出作为Reduce阶段的输入,在这个阶段,系统会根据键对中间键值对进行排序和分组,以确保具有相同键的值被发送到同一个Reduce任务。
Reduce阶段
Reduce阶段的任务是处理中间键值对并生成最终结果,Reduce函数接收一个键和一个值列表,然后将这些值合并为一个更小的值列表。
def reduce(key, values):
# 处理中间键值对并生成最终结果
...
相关问题与解答
问题1:MapReduce模型的主要优点是什么?
答:MapReduce模型的主要优点是其能够处理大量数据并利用分布式计算资源,它可以在多个节点上并行处理数据,从而提高处理速度,MapReduce还提供了容错机制,可以处理节点故障。
(图片来源网络,侵删)
问题2:在MapReduce中,如果一个节点失败怎么办?
答:在MapReduce中,如果一个节点失败,系统会自动重新调度失败的任务到其他节点上执行,这种容错机制确保了数据处理的可靠性,即使在大规模集群环境中也能正常工作。
(图片来源网络,侵删)
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/591600.html
 微信扫一扫
微信扫一扫