

MapReduce处理HTML输入

MapReduce是一种编程模型,用于处理和生成大数据集,它可以在分布式环境中运行,使得大规模数据处理变得可行,小编将详细介绍如何使用MapReduce处理HTML输入。
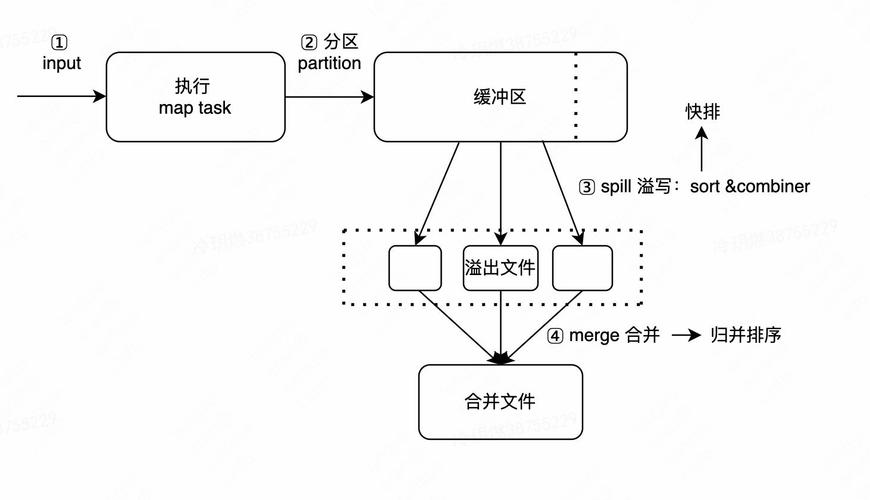
1. Map阶段
Map阶段的任务是将输入数据(在本例中为HTML文档)拆分成多个独立的键值对,每个键值对由一个键和一个值组成,其中键通常是数据的标识符,值是与该标识符相关的数据。
示例代码:
def map(html_content):
"""
Map函数接收HTML内容作为输入,并返回键值对列表。
"""
words = html_content.split() # 假设我们只是简单地按空格分割单词
kv_pairs = []
for word in words:
kv_pairs.append((word, 1)) # 使用单词作为键,值为1表示出现一次
return kv_pairs
2. Reduce阶段
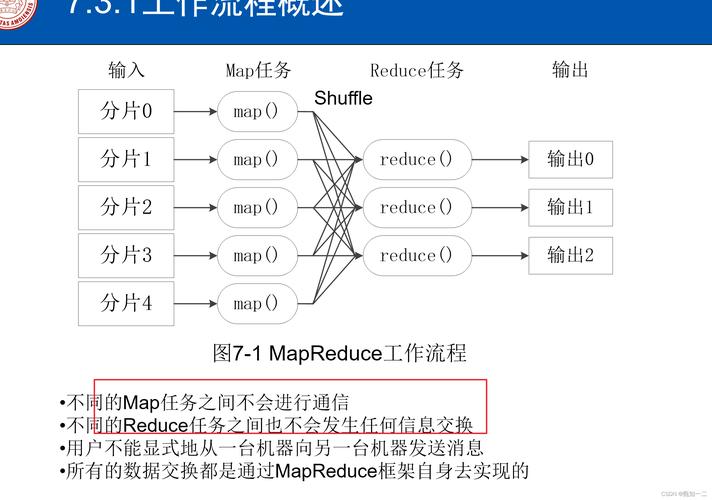
Reduce阶段的任务是对Map阶段的输出进行汇总和处理,它接收一组具有相同键的键值对,并对这些键值对进行处理以产生单个结果。
示例代码:
from collections import defaultdict
def reduce(kv_pairs):
"""
Reduce函数接收键值对列表,并返回一个字典,其中键是单词,值是单词出现的次数。
"""
word_count = defaultdict(int)
for key, value in kv_pairs:
word_count[key] += value
return dict(word_count)
3. 组合MapReduce
要将Map和Reduce阶段组合在一起,我们可以创建一个主函数来调用它们。
示例代码:
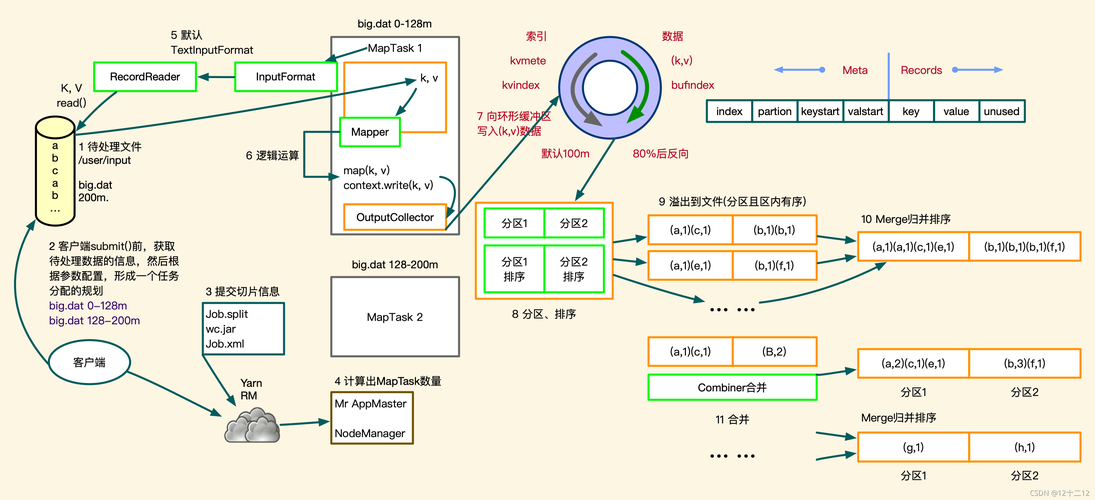
def main(html_content):
map_output = map(html_content)
reduce_output = reduce(map_output)
return reduce_output
相关问题与解答
问题1: MapReduce如何处理HTML中的标签?
答案1: MapReduce本身并不直接处理HTML标签,在Map阶段之前,需要先对HTML文档进行预处理,例如使用BeautifulSoup库或其他方法来提取文本内容,去除标签和其他非文本元素,可以将处理后的纯文本传递给Map阶段进行处理。
问题2: MapReduce如何优化大规模HTML文档的处理?
答案2: MapReduce非常适合处理大规模数据集,因为它可以在多个节点上并行处理数据,为了优化处理大规模HTML文档,可以考虑以下策略:
分块处理: 将大型HTML文档分成小块,并在多个节点上并行处理这些块,这样可以提高处理速度并减少单个节点的压力。
数据本地化: 尽量让Map任务在存储有相关数据的节点上运行,以减少数据传输的开销。
Combiner阶段: 在某些情况下,可以在MapReduce作业中使用Combiner阶段来减少网络传输的数据量,Combiner可以在Map阶段之后、Reduce阶段之前执行局部聚合操作,从而减少发送到Reducer的数据量。
原创文章,作者:K-seo,如若转载,请注明出处:https://www.kdun.cn/ask/591608.html
 微信扫一扫
微信扫一扫